我们正在向新域名迁移,3秒后自动跳转
We are migrating to new domain, will redirect in 3 seconds
jackwish.net -----> zhenhuaw.me
Android Neural Networks API —— 一种神经网络软件系统中间层的设计与实现
本文初作时基于的是 Android P Preview 4,即软件仓库中
android-p-preview-4版本。在 Android Pie 正式版(软件仓库中android-9.0.0_r1版本)发布后,笔者又检查了整体的实现,发现没有任何机制层面的改动,请读者放心参考。
随着深度学习的进一步发展,用于减轻框架层和硬件厂商开发代价的「中间层表示」以各种形式涌现:包括采用编译技术做图优化的、制定模型文件格式的、操作系统中间层的。本文重点介绍了操作系统中间层的代表 Android Neural Networks API 的软件架构、内部模块交互方式,并讨论了其设计。总体而言,Android Neural Networks API 简洁有效,符合软件系统的设计方法学。
引言
近年来,以人工神经网络为核心技术的深度学习取得了突破性进展,应用于图片分类、目标检测、语义分割、自然语言处理等领域的各种算法不断涌现。
深度学习的应用的一大特点是计算量极大(每层的计算量约是图片输入的特征和网络参数的乘数关系),在训练中大多采用 Nvidia GPU 来加速。随着行业的发展,特别是在终端设备上的推理需求逐渐增大,采用终端上的 GPU、DSP、ASIC等硬件设备计算的需求愈发广泛。另一方面,用于开发应用的上层框架也不断丰富。
丰富的上层框架应用和底层硬件设备带来了一个问题——每一种上层空间都要尝试适配主流的硬件设备,每一种底层硬件设备上都要适配主流的框架应用。这种工程任务是如此的繁重,因而对产业中所有的角色都是不利的。
针对这样的问题,多种中间层被提出。这样的中间层可以支持多个应用框架和多个设备(起码目标是这样)。其特别之处在于框架和设备都只需要对接到这样的中间层,而不需要对接到每个框架或设备,大大降低了开发成本。
这样的方案主要包含三大类:
-
图优化编译技术:以 Intel nGraph 和 TVM 为代表。强调自身采用特定的中间表示,对前端框架传递过来的计算图做计算优化,优化结果编译后在传递给后端设备。这种方法汲取了 LLVM 的设计思路。
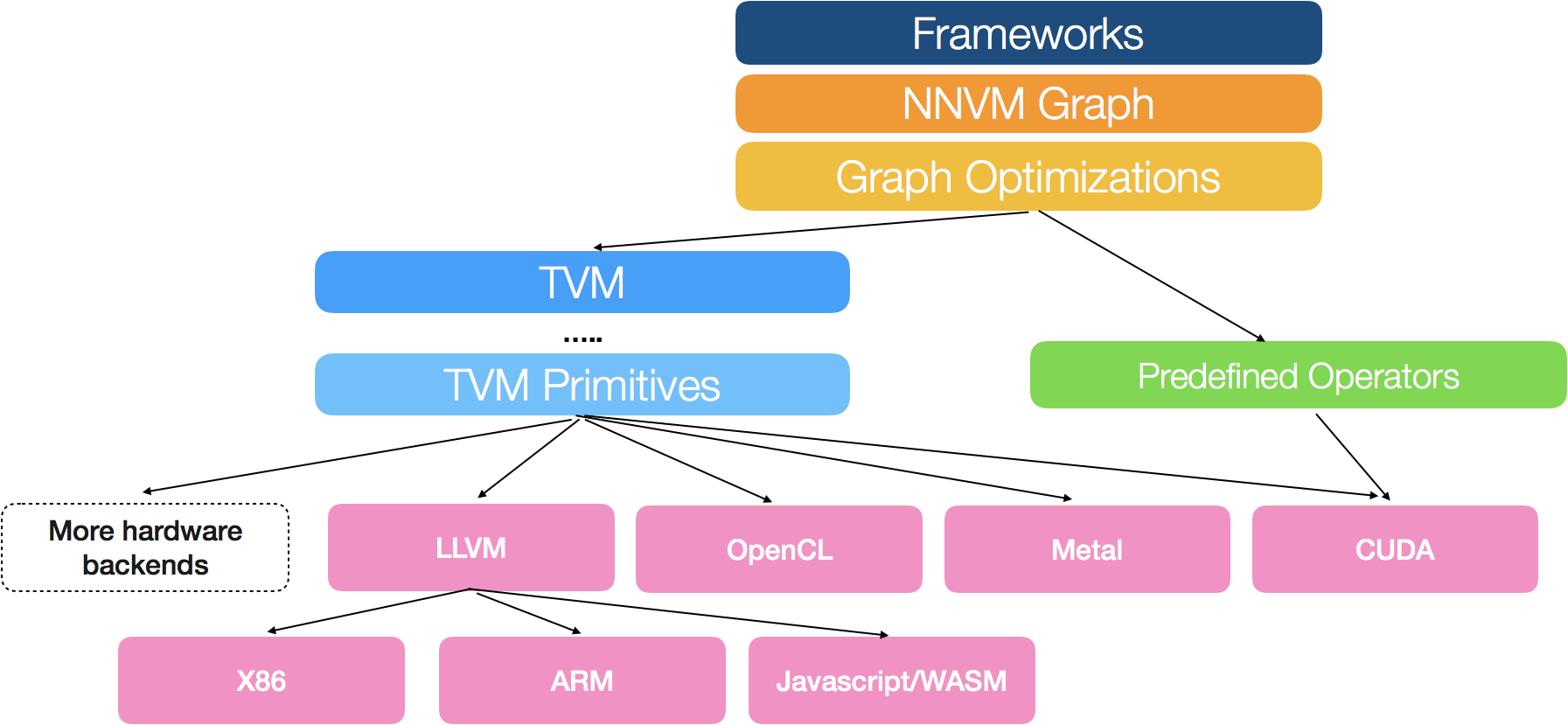
-
模型的描述方式:以 ONNX 和 NNEF 为代表。强调前端框架输出一个抽象化的模型描述,后端推理时读取这个描述。这基本上是在定义一种文件标准。
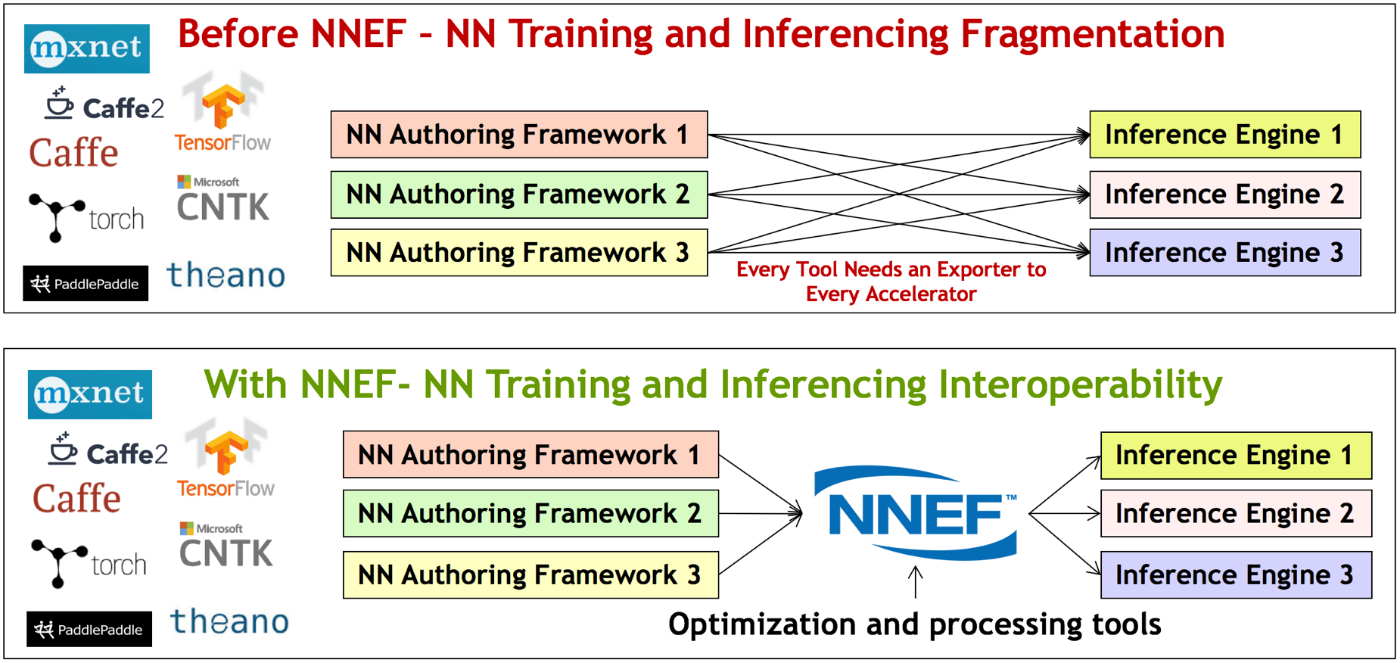
-
操作系统的接口支持:以 Android Neural Networks API(NNAPI)和 CoreML为代表。以降低最终产品中应用开发和设备上的开发代价为目标。
三类方法各有利弊。而有意思的地方在于,框架层或设备商对于支持前两种可能意愿不大。首先以编译为核心存在一个重大的问题——可能只适用于 CPU 这类能使用 LLVM 作为后端代码生成的,或者支持 OpenCL 的 GPU 硬件设备,对于产业中不断涌现的以寒武纪 MLU 和 Google TPU 为代表的深度学习硬件加速器不太友好。其次模型格式存在的问题是无法撼动占据统治地位的框架模型描述,例如当下的 TensorFlow 几乎成为了事实标准,这意味着 TensorFlow 模型实际上成为了这种「中间型」模型交换格式,另立标准毫无意义。这两种的缺陷总结到一点,缺乏在领域内占据主导地位的商业公司的推动,较难在短期内取得成功。当然,这里不是否认各种方法作为探究的价值,它们都会影响多年后的业界最终解决方案。
本文主要介绍 Android Neural Networks API 。首先操作系统接口方案是当前状态下最可能被多方接受的方案,毕竟关系到最终的产品形态,且和各家自己的类似产品不冲突。其次,相比于 CoreML 的封闭环境,Android 总体而言还是比较开源开放的,这使得我们能了解具体的实现方法。最后,Google 颇有携 Android 和 TensorFlow 两大神器号令「移动+人工智能」的趋势。
本文的剩余部分将首先介绍 Android Neural Networks API 的软件架构,然后介绍 Android Neural Networks API 的具体实现,之后介绍 Android Neural Networks API 的交互过程,最后总结 Android Neural Networks API 的特性。本文对 Android Neural Networks API 的介绍以 Android P Preview 4 为基准。
Android NNAPI 的软件架构
本节将分别介绍 Android Neural Networks API 的在整个软件栈中的形态、Android Neural Networks API 的编程模型、Android Neural Networks API 内部模块架构。
软件栈与接口
Android Neural Networks API 致力于为高层机器学习框架提供用于构建和训练神经网络的基础功能层。关于 Android Neural Networks API 的角色定位请参考官方文档。
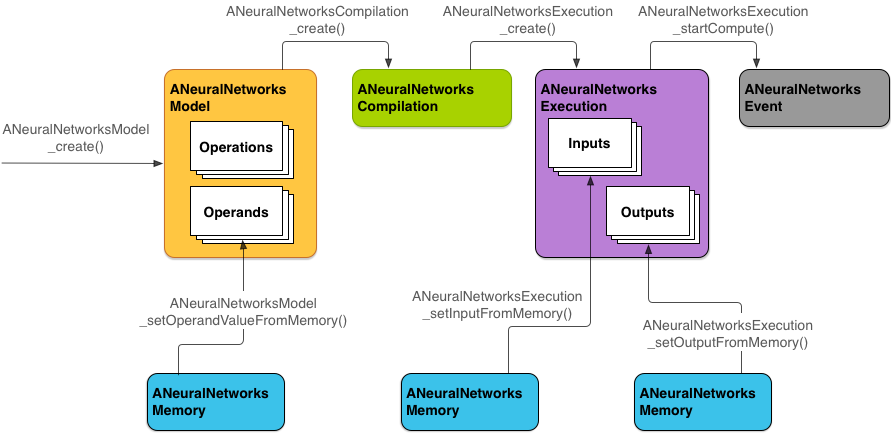
下图是 Android Neural Networks API 的软件栈,图中箭头表示了调用关系。 作为操作系统一部分,同时又是和底层设备高度相关的一套系统,Android Neural Networks API 的接口包括两部分:高层用户侧的 NDK 接口(图中 Android NN API)、和底层硬件设备侧的 HAL 接口(途中的 Android NN HAL)。
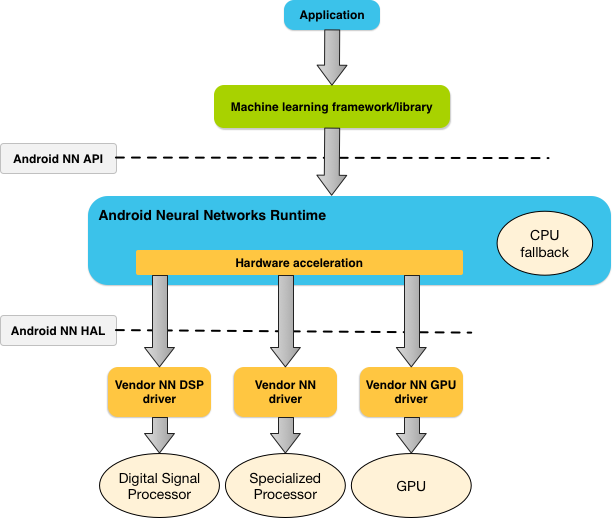
其中,NDK 接口是一组包含在 NDK 之中的 C 风格接口。通常这层接口的正确性由 CTS 确认。如图中所示,这一层是设计给深度学习框架使用的。当然,Android 应用也可以直接使用这一层接口,但似乎没什么必要。因为应用开发者直接使用 TensorFlow Lite、PyTorch/Caffe2 这类框架,框架后端对接 Android Neural Networks API (目前 TensorFlow Lite 和 PyTorch/Caffe2 已经集成)。接口包括常见的网络定义、编译、执行等步骤,具体参见下文的编程模型和实现介绍。
HAL 接口是一组用 HAL Interface Definition Language(HIDL) 描述的接口。HIDL 是 Android Oero 引入的全新的用于操作系统和硬件设备交互的机制。通常,VTS 检验设备提供的底层实现的正确性。引入 Android Neural Networks API 之后,硬件供应商在 Android 平台上只需要支持 HAL 接口这一层,继而从繁杂的框架支持中解放。从图中可以看到,在一个系统中可以存在多个不同种类的后端驱动设备。
Android Neural Networks API 包含一个 Runtime 。Android Neural Networks Runtime 的功能并不复杂,主要目的还是为了对接后端硬件。同时,考虑到硬件驱动在特定功能(例如某个新的神经网络算子)的可用性,Android Neural Networks Runtime 还包含了 CPU 回退(fallback)的功能——当不能使用专用设备计算时,依然可以保证基本的功能——这就像在图形系统中也可以用 CPU 模拟图形设备。Runtime 将在 Android Neural Networks API 内部结构等小节中继续介绍。
编程模型
对于任何机器学习系统,我们都可以将其任务分为三个步骤:
- 从用户那里获得计算模型的定义
- 对计算模型施以某些优化,使得计算能更快地进行
- 在硬件设备上执行计算模型
上图所示的 Android Neural Networks API 的编程模型定义也绕不开这三大步骤。下面我们用 Android 官方提供的示例来说明具体的过程。这个简单的网络只包含两个算子(加法和乘法)和六个张量。下图是网络示例。
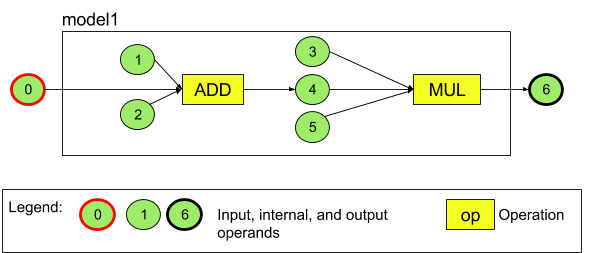
首先用户需要创建模型,并向模型中添加模型的算子(Operation,如卷积)和操作数(Operands,包括张量和标量,后文将均以张量描述。张量包括网络的输入和权重)。值得注意的是,网络模型中的张量都是以添加到模型中的顺序序号为标识符的。在描述算子的输入输出时也是使用的这些序号。这一步的代码看起来会比较冗长,但这对所有的深度学习系统来说应该都是一致的——毕竟最复杂的就是模型定义。
ANeuralNetworksModel* model = NULL;
ANeuralNetworksModel_create(&model);
// define the operand
ANeuralNetworksOperandType tensor3x4Type;
tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32;
tensor3x4Type.scale = 0.f; // These fields are useful for quantized tensors.
tensor3x4Type.zeroPoint = 0; // These fields are useful for quantized tensors.
tensor3x4Type.dimensionCount = 2;
uint32_t dims[2] = {3, 4};
tensor3x4Type.dimensions = dims;
// skip rest operand definition...
// Now we add the seven operands, in the same order defined in the diagram.
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1
ANeuralNetworksModel_addOperand(model, &activationType); // operand 2
// skip other examples...
// In our example, operands 1 and 3 are constant tensors whose value was
// established during the training process.
const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize.
ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor);
ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5.
int32_t noneValue = ANEURALNETWORKS_FUSED_NONE;
ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue));
ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));
// We have two operations in our example.
// The first consumes operands 1, 0, 2, and produces operand 4.
uint32_t addInputIndexes[3] = {1, 0, 2};
uint32_t addOutputIndexes[1] = {4};
ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// skip another operation example
// Our model has one input (0) and one output (6).
uint32_t modelInputIndexes[1] = {0};
uint32_t modelOutputIndexes[1] = {6};
ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
ANeuralNetworksModel_finish(model);
然后将定义好的模型编译。这一步用户可以设置编译的一些偏好,例如是高性能模式还是低功耗模式,这会影响后续编译和运行环节的一些系统决策。
// Compile the model.
ANeuralNetworksCompilation* compilation;
ANeuralNetworksCompilation_create(model, &compilation);
// Ask to optimize for low power consumption.
ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
ANeuralNetworksCompilation_finish(compilation);
最后再给定模型的输入输出内存,运行模型。由于模型可能非常大,计算比较耗时,Android Neural Networks API 在计算这一步引入了异步事件——用户通知 Android Neural Networks API 运行模型后便进入等待状态,直到 Android Neural Networks API 完成计算。另外,深度学习中模型的权重和输入输出往往都是非常大的,因此还需要辅以内存管理。
// Run the compiled model against a set of inputs.
ANeuralNetworksExecution* run1 = NULL;
ANeuralNetworksExecution_create(compilation, &run1);
// Set the single input to our sample model. Since it is small, we won’t use a memory buffer.
float32 myInput[3, 4] = { ..the data.. };
ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
// Set the output.
float32 myOutput[3, 4];
ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
// Starts the work. The work proceeds asynchronously.
ANeuralNetworksEvent* run1_end = NULL;
ANeuralNetworksExecution_startCompute(run1, &run1_end);
// For our example, we have no other work to do and will just wait for the completion.
ANeuralNetworksEvent_wait(run1_end);
当然最后用户还需要销毁不再使用的描述符等。这里不再赘述。
架构中的各个模块
到此为止,我们已经介绍了较高层面的接口概念。本小节将介绍 Android Neural Networks API 的各个模块结构。
下图是 Android Neural Networks API 软件栈的细化架构。NDK 接口之上是 Android 应用,应用中一般应该打包一个深度学习框架(例如 TensorFlow Lite)和一些网络模型(例如 InceptionV3)。HAL 接口之下是设备供应商的驱动。一般而言,供应商都会有自身的神经网络的运行时(图中的 Vendor NN),例如 ARM NN。那么在 Android Neural Networks API 系统中,供应商需要将自身的运行时图中的 HAL Wrapper 集成到 Android 系统中,例如 ARM Android NN Driver 。整个架构的最下层就是各种各样的硬件设备,典型的硬件包括 GPU、DSP 和现在创新比较多的神级网络处理器(Neural networks Processing Unit,NPU)。

架构的中间部分即是 Android Neural Networks Runtime ,主要包括四大部分(图中着色不同),下面将依次介绍。
首先是着色为浅蓝色的四个组件。这四个是和 NDK 界面联系紧密的组件,当用户调用 NDK 接口时,实际上是和这四个组件交互。
- ModelBuilder 拥有整个网络的描述,包含了算子、张量、内存等。从 ModelBuilder 中可以创建出 CompilationBuilder
- CompilationBuilder 是“编译”用的接口,从中可以创建 ExecutionBuilder
- ExecutionBuilder 可能是整个过程中占主导地位最多的模块。事实上,编译、执行等都是通过与它的交互完成的(这个细节我们可以暂时忽略)
- Memory 是内存管理部分,它用于传递参数内存和输入输出内存,贯穿应用的整个生命周期
中间着色为绿色的部分是 Android Neural Networks API 当前最为复杂的模块。这部分管理模型在多个设备间的划分工作。我们在介绍 Android Neural Networks API 架构时曾提到过,设备驱动支持的算子集合可能是有限的——是 Android Neural Networks API 支持的算子的子集——那么就出现一个在机器学习系统领域常见的问题,一个模型的不同部分可能需要在不同的硬件设备上运行。对于这一问题通常有两种解决方法:
- 每个算子都单独地在某个设备上运行。这种方法比较简单,但可能会引入潜在的性能问题,一般只有 Caffe 这样的早期框架使用。
- 划分子图。将网络划分成不同的部分(连通图),使得每个部分能在同一硬件上运行,并使得每个部分尽量大。一般现代框架都采用这种方法。
Android Neural Networks API 虽然推出时间不长,但设计已经比较完善,目前采用的是划分子图的方法。绿色部分即为网络划分,和管理各个部分执行的模块。特别的,Android Neural Networks API 的划分不仅根据设备是否支持,还根据各个设备的性能、功耗,以及用户运行的偏好来制定划分方法。
具体的划分工作由 ExecutionPlan 主导以及其他多个模块共同完成。ExecutionPlan 还和其他两个模块协作,从而控制网络划分后的执行过程。
- Controller 控制着一次网络执行的状态,记录着当前执行到了多少步(ExecutionStep)
- ExecutionStep 是网络拆分出的子网络。每个 ExecutionStep 都完整地在一个硬件设备上运行
着色为红色的部分是 Android Neural Networks API 具体某个执行步骤在执行过程中的控制器。
- StepExecutor 在 Controller 的控制下将一个 ExecutionStep 分配到某个硬件上执行
- CPU Fallback 在回退到 CPU 运行时使用。它包含一个小的 runtime 和在 TensorFlow Lite 实现的算子
最后,着色为黄色的 DeviceManager 负责管理并进一步抽象底层设备。抽象的工作包括抹除 Android Neural Networks API 不同版本间的差异。
以上就是 Android Neural Networks API 软件栈中各个模块的介绍。下面我们将在代码层面更加详细地介绍 Android Neural Networks API 的具体实现。
Android NNAPI 的实现细节
本节介绍 Android Neural Networks API 的实现细节。这部分信息更加细化,请结合具体的代码以及前述的模块功能加以理解。
特别说明:本节基于 Android P Preview 4 的代码介绍,在查看具体代码时请切换到 android-p-preview-4 git 标签。
HAL 层接口
位置:aosp/hardware/interfaces/neuralnetworks
HAL 库([email protected])包含了一组硬件设备供应商要实现的功能,现在有 1.0 (Android 8.1)和 1.1 (Android 9.0)两个版本。其中的接口又可以分为多个部分。
IDevice.hal
| 接口 | 说明 |
|---|---|
getCapabilities |
获取硬件的功能 |
getSupportedOperations |
检查硬件支持模型中的那些算子,结果以 vector<bool> 返回 |
prepareModel |
异步地“准备”模型。将 Android Neural Networks API 定义的模型提供给底层实现,底层实现可以将其转换为自己的格式。转换结果通过回调函数通知 Android Neural Networks API 。 |
getStatus |
获取状态 |
Android Neural Networks API 的 prepareModel 出发点是让底层驱动做包括:模型转换(Android Neural Networks API 到 驱动自身描述)、图优化、常量内联、编译等。prepareModel 结束的含义是上层可以运行这个网络了,至于驱动的优化做到什么程度,这不是 Android Neural Networks API 关系的事情。
接口 prepareModel 还包含 IPreparedModel 等内容,见下面的其他三个 HAL一节。
types.hal
types.hal 包含大量的神经网络相关的 operation 和 operand 描述。在此之外,还包含了对模型的描述、对数据的内存布局的描述等等。看起来似乎两个版本差异不大。在模型描述中,采用的方式和 caffe 有点类似,使用 vector 作为容器,且输入输出的描述直接使用 operand 的索引。这让底层实现可以做得比较简单……
张量(operand)的类别以数据类型和生命周期区分。
- 数据类型比较直观,生命周期包含几种:临时变量(网络“内部”的张量,即非输入输出,非参数的张量)、输入/输出、常量(网络的参数)。
- 张量名为 operand 。operand 包含张量和标量两种,张量带
TENSOR_前缀。 - 张量的数据结构描述了张量的类型、维度、后继算子数量、量化的缩放系数和偏移、生命周期、内存地址等。
- 其中,张量的维度可以是未指定的,因为这可以从输入中一步一步推算出来,但确定的维度可以帮助网络的编译优化。
- 当然,参数、输入输出还是需要明确指定维度的。
- 内存以 内存池索引 + 池内偏移 + 长度 描述。
算子(operation)算子的数据结构比较简单,只包含类型、输入张量的索引、输出张量的索引。对于比较关键的参数,还不确定是如何描述的:直接对 operand 用 CONSTANT 描述,算子层面只描述有那几个 operand ,对这些 operand 的使用交给底层驱动。
模型(model)包含了图、常量等信息,唯一缺乏的可能是输入张量的形状。
- 模型中以数组形式记录了张量、算子、输入输出张量的索引、张量值、内存池等。
- 对于张量的数据,张量值和内存池分别记录了生命周期为
CONSTANT_COPY和CONSTANT_REFERENCE类型的张量数据。
RequestArgument 描述一个张量的“更新信息”,包含内存地址和形状变化信息(维度不可变)。似乎只用于网络的输入输出。 Request 是对 RequestArgument 的包装,包含若干个输入、输出和对应的内存池。Request 有两个主要任务:
- 在运行网络时提供输入输出数据
- 给出“模型准备时期”没有指定的输入张量的元信息
Capability 包含设备的性能数据。性能包含执行时间和功耗,以设备相对于 cpu 的比率记录。这是一种粗粒度的记录,只包含 float32 性能和 8bit 量化性能。
版本 1.1 的几个改的包括:
-
getCapabilities和Capabilities包含了“relaxed calculation”(使用 float32 的数据,但计算时使用 float16 的精度)性能。 - 增加了一些算子的支持。
- 执行的偏好——低功耗、快速等。1.0 没有放到 HAL 这一层吗?
其他三个 HAL
IPreparedModelCallback:当 prepareModel(Model, IPreparedModelCallback) 执行完毕后,驱动应当调用 IPreparedModelCallback.notify(IPreparedModel) 来通知 Android Neural Networks API 模型已经准备完毕,可以运行了。由 Android Neural Networks API 提供给 HAL 驱动。
IPreparedModel 是一个可执行的模型,由 HAL 驱动提供给 Android Neural Networks API 。和 prepareModel 类似,IPreparedModel 中的 execute 方法也是异步的。execute(Request, IExecutionCallback) 传递了网络的输入输出 Request 和一个通知 Android Neural Networks API 网络执行完毕的回调函数。IPreparedModel 的内部实现对 Android Neural Networks API 无所谓,而其中的 execute 方法由 Android Neural Networks API 调用。
IExecutionCallback只包含一个状态返回。网络的输出结果内存已经在 IPreparedModel.execute() 中给定。当 HAL 驱动执行完网络,调用IExecutionCallback.notify() 方法是,Android Neural Networks API 只需要回去检查 execute() 方法当时给定的 Request 即可得到输出。
VTS(Vendor Test Suite)
vts 背景可以参考 https://source.android.com/compatibility/vts/
Android Neural Networks API 的 VTS 包含了上面所有接口的测试,即算子、张量、模型和 runtime 等。在大多数时候,抛开测试的大背景,这里的 VTS 主要在模拟 libneutalnetworks.so 的行为去使用 android.hardware.neuralnetworks@1.[0|1].so 。下面将重点介绍 libneutalnetworks.so 。
核心系统
位置:aosp/frameworks/ml/nn
这部分包含了 Android Neural Networks API 的 runtime、暴露给开发者的 NDK 接口等。
driver sample
可以看到,驱动主要的工作是继承 IDevice 之类的类,并实现其中的方法。驱动将以服务的形式注册到系统中,SampleDriver::run() 。Android Neural Networks API 的 runtime 则通过 HAL (via android.hardware.neuralnetworks.so) 的方式使用底层驱动。
示例中提供了多种配置的驱动类型,展示了如何去配置性能 getCapabilities_1_1 和简单的 getSupportedOperations_1_1 实现。不清楚在 HIDL 的体系中,当有多个 HAL 驱动实现时,Android Neural Networks API 会如何处理,遍历所有设备找到合适的?:针对单个算子选择最优设备。
common
一些基础性的实现,被多个模块共享。
Operations :common/operations 存放的是 cpu 实现的算子。这些算子的最终计算使用的是 TensorFlow Lite 中的实现(tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h)。这里的代码是对 TensorFlow Lite 算子实现的一种封装。(注意,在 Android Neural Networks API 中,cpu 实现只是一种备选方案,并不意味着 Android Neural Networks API 和 TensorFlow Lite 的结构是混杂的。)算子的声明在 common/include/Operations.h 中。CpuExecutor.cpp 会将计算任务分配到各个算子。
CpuExecutor 是 cpu 上的执行引擎。
-
RunTimeOperandInfo:包含张量的类型、维度等——和 HAL 层中的信息量差不多,不过号称这里是可更改的。 -
RunTimePoolInfo:封装了IMemory作为内存池。内存有ashmem和mmap_fd两种 HIDL 方式,也有直接给定缓冲区地址。(即共三种) -
CpuExecutor:run方法接收模型、模型内存池、输入输出、输入输出内存池等,按照 Model 中的顺序依次执行算子。由StepExecutor::startComputeOnCpu()调用。执行步骤包括:-
initializeRunTimeInfo输入参数配置这里的“小 runtime”的张量、内存信息。 - 遍历
Model.operations[]中的算子,依次用executeOperation执行。根据算子的类型校验算子的输入输出张量数目,然后调用算子的对应实现(common/operations) -
CpuExecutor还会追踪张量被使用的情况,主动地回收不再使用的张量内存。
-
其他,common 中还包含一些“基础设施”代码:
-
GraphDump可以将网络定义转成 Graphviz 格式呈现。测试使用的小工具,没有加入到执行流中。 -
Traceing主要为了抓取 Android Neural Networks API 的执行时间,也可以监视驱动、cpu各自的执行时间和调用序列。Tracing 包含插入代码中的宏定义、android systrace、systrace parser 等。有尚未公开的文档 NNAPI Systrace design and HOWTO 。 -
ValidateHal验证 HAL 的各种数据结构类型及其约束。
runtime
对上层(TensorFlow Lite)的接口: https://android.googlesource.com/platform/frameworks/ml/+/master/nn/runtime/include/NeuralNetworks.h
核心系统中的接口
这部分包含 NeuralNetworks、(Device)Manager、VersionedIDevice 等。
NeuralNetworks 包含接口相关的实现。这一层似乎不维护任何数据或结构,C 风格的接口导致资源都是由上层(框架)维护。Android Neural Networks API 上层接口的数据结构和 HAL 层定义的接口的数据结构基本上类似——去掉 ANeuralNetworks 前缀。
DeviceManager 是单例模式,因此只有一个集中化的 DeviceManager。Android Neural Networks API 使用多个后端设备,它们通过 DeviceManager 管理。
- 构造时从 ServiceManager 中找到所有的 Android Neural Networks API 设备,将其记录下来。上层通过
getDrivers()获取所有的可用设备。 - 所有的设备以
<name, Device>的形式识别,管理使用简单的 Device 数组。 - 记录了划分策略。一共三种策略:
- 不划分
- 划分,如果划分失败就回退到不划分的模式
- 划分,但禁止回退
Device 封装了 VersionedIDevice,记录 <name, IDevice>。
- Device 记录 VersionedIDevice 对象和设备的性能参数。
- 上层逻辑在使用设备时一般是
DeviceManager::getDrivers()[i]::getInterface()::*而不是直接使用 Device,比较奇怪。但getSupportedOperations使用的是 Device ,看起来是在做容错—— 当和设备的通信失败时,将该设备标记成不支持任何算子。
VersionedIDevice 负责管理版本,将不同版本的差异对 runtime 的其他部分屏蔽。方法也比较简单:一个设备必定是 1.1 或 1.0 版本,如果是 1.1 版本,那么直接使用;如果是 1.0 ,对不支持的接口按语义给出兼容结果。
助手功能
Memory 是内存管理组件。(内存管理这一块现在还没弄清楚)
-
Memory作为基类,使用的内存是通过 HIDL 机制分配的,这种内存可以在驱动和 HAL 层使用。 -
MemoryFd继承了Memory-
MemoryFd使用的内存是通过mmap(fd)分配的,内存会转换为 HIDL 描述后记录。即,Memory和MemoryFd虽然内存的创建方式不一样,但后续的使用方法一致的。 - 外部接口总是从文件创建内存对象
MemoryFd——ANeuralNetworksMemory_createMemoryFd()
-
-
MemoryTracker是用来管理Memory的工具,方便上层同时管理多个 Memory 对象。- 使用者包括
ExecutionBuilder,StepExecutor,ModelBuilder。 -
目前不清楚
Memory和DataLocation之间的关联——在 HAL 层中,模型的内存是在 Model 中管理的。
- 使用者包括
Callbacks 是 Android Neural Networks API 和 HIDL 驱动线程之间同步的主要方法。
- 异步任务总是会绑定一个 Callback 对象。所有的回调都要继承
CallbackBase。 -
CallbackBase的接口包括:-
wait将阻塞直到notify;wait_for也会阻塞,不过带超时功能 -
on_finish(func)设置一个函数,该函数在notify时执行(在阻塞线程 wakeup 之前) -
bind_thread和join_thread提供了资源回收的方法。具体目的还不清楚 -
notify唤醒阻塞线程。这里会先执行on_finish设置的post_work,然后唤醒所有线程。
-
-
PreparedModelCallback继承了CallbackBase和IPreparedModelCallback- 这是 Android Neural Networks API 通过 HIDL 传递给 HAL 驱动的回调,HAL 驱动会给 Android Neural Networks API 一个
PreparedModel
- 这是 Android Neural Networks API 通过 HIDL 传递给 HAL 驱动的回调,HAL 驱动会给 Android Neural Networks API 一个
-
ExecutionCallback继承了CallbackBase和IExecutionCallback- 这里不需要传递数据,只需要传递执行完毕的状态
ModelBuilder
ModelBuilder 内部存储了用户通过 ANeuralNetworksModel_* 系列接口创建的算子、张量等。
张量与内存管理
-
setOperandValue可以指定张量的内存。- 根据内存大小(128字节),采用拷贝或引用的方式存储数据。
- 拷贝的数据都存在
mSmallOperandValues数组中;引用的数据存在mLargeOperandValues中(直接拿缓冲区指针)。 - 看起来这个接口专门用于指定常量–网络参数。
-
copyLargeValuesToSharedMemory- 通过 HIDL 创建一块内存,将所有的引用型常量拷贝到这块内存中
- 在
finish时被调用,能有效地减少内存碎片。
-
setOperandValueFromMemory- 可以指定在特定
Memory中的参数 - 以引用形式记录该这块参数,在
copyLargeValuesToSharedMemory时被合并
- 可以指定在特定
-
identifyInputsAndOutputs将修改输入输出张量的生命周期为输入输出,也会更新输入输出数组。
运行过程、流程
-
sortIntoRunOrder对算子排序,确保算子的运行顺序是正确的–满足拓扑排序- 首先建立”张量和使用某个张量的算子”映射、某算子还有多少个输入没区别出类型,并将输入算子标记为”可计算”
- 执行循环:从”可计算”的集合中取出一个算子,将其加入到执行顺序中。那么,该算子的输出是可得,所有”使用该算子输出作为输入”的算子的”尚为计算出的输入”数量减一。扫描所有算子,将所有输入都可知的算子加入到计算任务中
- 在循环结束后,所有的算子都拥有了正确的执行顺序
-
finish表示完成了模型的配置,步骤包括-
identifyInputsAndOutputs(应该在finish之前调用) -
copyLargeValuesToSharedMemory会固化参数 - 对模型进行验证工作,确保符合 HAL 描述
sortIntoRunOrder
-
和其他模块对接
-
createCompilation创建一个编译对象,因为编译要和模型对应起来 -
findBestDeviceForEachOperation和制定执行计划的ExecutionPlan息息相关。- 针对每个算子,找到执行该算子最优的设备
- 最优设备,性能优先时看执行速度,功耗优先时看功耗分数
-
partitionTheWork划分计算任务,在ExecutionPlan中实现 -
setHidlModel修改 Model 中的算子、张量、输入输出、内存池等。用在任务划分建立的”子模型”和验证模型中
partitionTheWork 是划分任务。在 ModelBuilder 中声明,在 ExecutionBuilder 中定义,在 CompilationBuilder::finish() 中使用。
- 如果只有 cpu ,那么不划分任务
- 使用
findBestDeviceForEachOperation找到算子的最优设备。如果所有算子的最有设备都是同样的设备,那么不划分任务 - 任务划分的两个核心步骤如下
- 为每个设备创建一个算子队列,根据最优设备将算子加入到各个队列中
- 为每个设备创建执行步骤
ExecutionStep,将设备的算子队列加入到任务中 - 这个过程中包含了和
sortIntoRunOrder非常类似的排序工作,进入队列的算子是那些已经完全清楚了计算顺序的算子
- 结束划分
ExecutionPlan::finish
CompilationBuilder
CompilationBuilder 是从 Model 创建的对象。
- 虽然名为编译,但在接口上并没有体现编译,更多的是记录设备和用户的编译相关的偏好信息——性能和划分等。
-
createExecution是在“编译”完成后创建执行对象 -
finish调用partitionTheWork划分执行任务。当划分失败时,如果可以回退,那么会忽略划分错误。
ExecutionBuilder
ExecutionBuilder 是另一个比较重要的模块,它从 CompilationBuilder 创建。
ModelArgumentInfo 是模型输入输出的描述,信息主要包括维度形状和内存。其中内存可以以指针、Memory 等多种形式指定。每个 ModelArgumentInfo 描述一个输入/输出,多个以数组形式组织。
ExecutionBuilder 是高层接口的运行逻辑。
- 在高层接口中以
ANeuralNetworksExecution_*接口大多是在配置输入输出。startCompute是核心逻辑接口。 -
startCompute(ExecutionCallback)中,上层应用和下层 HAL 驱动是异步的(在其他的 finish 接口中,应用和 Android Neural Networks API 是同步的,Android Neural Networks API 和 HAL 驱动是异步的)。
ExecutionBuilder::startCompute 的核心逻辑根据(编译选项)是否需要划分任务又分两种情况。
- (编译选项)划分任务的情况
- 使用
ExecutionPlan::makeContrioller构造运行控制器- 如果控制器构造失败,且允许回退,那么会退到 cpu 模式执行(使用
StepExecutor::startCompute)
- 如果控制器构造失败,且允许回退,那么会退到 cpu 模式执行(使用
- 启动线程异步地执行
asyncStartComputePartitioned,立即将 ExecutionCallback 对象当做 Event 返回给应用。 -
asyncStartComputePartitioned是一个包含下面循环的函数- 从 ExecutionPlan 中取出下一个 StepExecutor 。(成功则继续,失败则全部回退到 cpu 或报错)
- 创建 ExecutionCallback 并执行刚取出的 StepExecutor 子任务。(成功则继续,失败则这部分回退到 cpu 或报错)
- 等待任务执行完毕(成功则继续,失败则这部分回退到 cpu 或报错)
- 当执行整个网络时,使用 ExecutionBuilder 构造 StepExecutor;当执行部分网络时,一般使用 ExecutionPlan 构造 StepExecutor 。
- 使用
- (编译选项)禁止划分任务的情况
- 找到一个能支持所有算子的设备
- 映射输入输出,
StepExecutor::startCompute
StepExecutor 是执行“一步”计算的对象,要求在单一设备上运行。
- StepExecutor 也有不少内容在处理各种形式的输入输出的内存。
-
allocatePointerArgumentsToPool将外部提供的输入输出内存(Memory)记录到 StepExecutor 中。缓冲区、参数的起始地址等均依赖于之前提供的操作数信息。
StepExecutor::startCompute 执行最终的计算任务,分为 cpu 和设备上两种情况。
-
startComputeOnCpu在 cpu 上运行- 创建用于 HIDL 的模型并拷贝模型信息、设置输入输出、内存池等
- 创建 ExecutionCallback
- 启动线程
asyncStartComputeOnCpu异步地计算,并立即将 Callback 对象传递给上层(最终作为 event 传递给用户)- 计算线程创建 CpuExecutor 来运行网络,并在结束后用 Callback 通知上层执行结束的状态
-
startComputeOnDevice在设备上执行- 如果设备上的模型(IPreparedMOdel)尚未生成,则要先生成。生成完毕后继续
- 创建 IPreparedModelCallback 后调用
IDevice::perpareModel()生成模型 - 在生成完毕后,驱动将 IPreparedModel 传递到这里,Android Neural Networks API 记录下
- 创建 IPreparedModelCallback 后调用
- 类似地,针对各种情况配置好输入输出;创建 ExecutionCallback
- 调用
IPreparedModel::execute()执行计算。计算将异步地执行,但 Android Neural Networks API (暂时)会在这里同步等待。(以后应该会删掉这个同步操作) - 检查状态、根据情况同步输出数据
- 将 ExecutionCallback 返回给上层。(目前这里的计算是同步的,以后应该会改成异步的)
- 如果设备上的模型(IPreparedMOdel)尚未生成,则要先生成。生成完毕后继续
ExecutionPlan
一个 ExecutionPlan 由若干个 ExecutionStep 组成。ExecutionStep 的执行由 ExecutionPlan::Controller 控制,它和每个 ExecutionStep 一一对应。每个 ExecutionStep 都拥有自己的 ModelBuilder ,当然这个 ModelBuilder 的内部不再是可划分的。Controller 之间用 ExecutionStep 在 ExecutionPlan 中的索引串联起来,这些串联关系构成了 ExecutionStep 之间的拓扑关系。
ExecutionStep 是“一次运行”的粒度,拥有自身的模型、设备、输入输出等。
- 其中模型的算子、张量均来自于“母模型”,因此维护了一系列映射。
- 这些映射有
<fromModel index, subModel index>,也有相反的映射 - 主要用于描述子模型的输入输出——这些张量在母模型中可能是输入、输出或临时张量,甚至输出作为输入之类
- 也有“集中式”描述子模型输入输出到母模型的索引,和描述所有张量的映射
mOperandMap
- 这些映射有
-
addOperand增加新的被分配到“本执行步骤”的张量- 这些张量的信息(类型、维度、内存等)会通过 ModelBuilder 接口添加到
mSubModel - 这里更新
mOperandMap,还根据情况张量在母模型和子模型中的属性更新相应的映射 -
有一点值得注意,更新映射时使用了
OperandKind::[INPUT|OUTPUT]**,这本来是应该根据“子模型”输入输出来设置映射,但addOperation调用addOperand时给出的却是“算子的输入输出”。不确定这里是不是有问题。**
- 这些张量的信息(类型、维度、内存等)会通过 ModelBuilder 接口添加到
-
addOperation增加新的被分配到“本执行步骤”的算子- 将算子的输入输出加入到 ExecutionStep 中。这里将算子的输入输出作为了子模型的输入输出,不确定是否合理
- 将算子信息添加到
mSubModel中,添加时使用的输入输出张量索引是以子模型为基准的
-
finishSubModel在ExecutionPlan::CompoundBody::finish()中被调用,完成某个子模型运行前的“准备工作”- 首先进一步更新子模型的输入输出,并设置给
mSubModel - 调用
compile完成从 Android Neural Networks API 模型到 HIDL 驱动 IPreparedModel 的转换。compile会阻塞直到转换完毕
- 首先进一步更新子模型的输入输出,并设置给
ExecutionPlan 是模型的整个执行计划。
- ExecutionPlan 内部定义了多个辅助对象
-
Controller- 记录了 ExecutionPlan 和 ExecutionBuilder,通过
ExecutionPlan::makeController构造 -
mNextStepIndex记录了,在所有的执行步骤中,下一次要执行的步骤的索引——标记了执行状态 - 没看出来有什么特别的作用
- 记录了 ExecutionPlan 和 ExecutionBuilder,通过
-
Body是一个基类。派生类有SimpleBody和CompoundBody两种-
SimpleBody负责执行“整个”模型,拥有设备、模型等。SimpleBody::finish()将用compile编译模型 -
CompoundBody在网络分步执行时使用,包含若干个 ExecutionStep 。CompoundBody::finish()依次调用各个ExecutionStep::finishSubModel()
-
-
- 网络分段与否的逻辑与信息
-
ExecutionPlan::mState记录了使用哪种模式,一般为分步网络 - 在
ModelBuilder::partitionTheWork划分网络时- 如果网络没有分段则用
ExecutionPlan::becomeSingleStep设置SimpleBody - 划分网络时,用
ExecutionPlan::createNewStep创建新的 ExecutionStep 来放置新的子网络。
- 如果网络没有分段则用
-
ExecutionPlan::createNewStep简单地用设备、步骤索引创建一个新的步骤。该步骤将被记录到ExecutionPlan::compound()::mSteps中
-
- 网络的分段运行中,ExecutionPlan 的主要任务是
next查找下一个执行步骤- 对于
SimpleBody整个网络,直接从模型、控制器、设备、准备好的模型中创建StepExecutor,并准备好模型的输入输出数据(整个网络的准备比较简单) - 对于
CompoundBory分步网络,选择“下一个”网络,用子模型、设备等创建StepExecutor。然后要设置好子模型的输入输出内存(这部分还是比较绕的) -
next在asyncStartComputePartitioned中被调用
- 对于
- 似乎,一个既定的网络模型可以有多个 Controller 控制某次计算
高通 HIDL 驱动层
Android P preview 中引入了一个使用高通硬件的 Android Neural Networks API HIDL 驱动后端:https://android.googlesource.com/platform/hardware/qcom/neuralnetworks/hvxservice/
这个驱动是薄薄的一层,代码量不到四千行。底层使用了 libhexagon_nn_controller.so (OnePlus 似乎也使用了这个库,但是没找到这个库是从哪里来的)和 Hexagon NNLib。
方便起见,我们将 AOSP 中的这个 HIDL 驱动称作 “HIDL驱动”,将更底层的接口称作 “DSP驱动”。
接口
HIDL驱动是中间层,因此这里又有两层接口:DSP 驱动的接口和 HIDL 驱动的接口。
DSP 驱动定义了又一套神经网络模型的接口,包括算子、张量、性能等数据结构,模型的准备、运行等接口。由于接口已经比较底层,算子的定义综合了精度等信息。
HIDL 驱动在 HexagonController 中将 DSP 驱动的 C 接口封装成 C++ 形式。底层的服务由 libhexagon_nn_controller.so 提供。这层封装是比较简陋的,只是相当于函数重命名而已。
这里只简单的介绍一下,几个简单的封装逻辑,驱动中将 Android Neural Networks API 描述和逻辑转换成 DSP 逻辑的将在其他部分重点介绍。
Device 是最外层接口,实现了 IDevice 的各个方法。
-
getCapabilities首先会配置 初始化 DSP 。float32 浮点的计算时间声明为 cpu 的 30 倍。 -
getSupportedOperations使用hexagon::Model::supportedOperations()。奇怪的一点是hexagon::Model用完就释放掉了。 -
prepareModel从 Android Neural Networks API 的Model构造了hexagon::Model,然后调用hexagon::Model::prepare()(该函数内部应该是异步执行的,这部分是同步的,异步已经在 Android Neural Networks API 中被处理掉了)。传递给上层时,构造了PreparedModel(model, hexagon::Model)。此时上层的Model和 HIDL 驱动的hexagon::Model才关联起来。
PreparedModel 继承了 IPreparedModel
- 记录了 Android Neural Networks API 的
Model和 HIDL 驱动的hexagon::Model对应关系。它们在Device::prepareModel中被关联起来 - 在上层 Android Neural Networks API 调用
execute方法时,最终使用hexagon::Model::execute()执行(应该是内部实现了异步,这部分是同步的,异步已经在 Android Neural Networks API 中运行网络时被处理掉了)
HexagonUtils 包含了一些将 Android Neural Networks API 表示转换成 DSP 表示的工具函数。包括枚举类型的映射,内存池到内存地址的转换计算等。
Device 在 Service 中用 hvx 向系统注册。注册的二进制程序为 /vendor/bin/hw/[email protected],将在系统启动(init)时注册。
HIDL 驱动的实现
HIDL 驱动的工作主要是将 Android Neural Networks API 表示的模型、数据转换成 DSP 的表示,并使用 DSP 提供的接口来运行计算任务。
由于最终的计算发生在 DSP 上,因此这里的算子也仅仅是作为转换功能使用。
- HexagonOperationsCheck 用作检查算子是否被 DSP 支持
- HexagonOperationsPrepare 是模型的帮助函数,负责将 DSP 支持的算子加入到模型中,是模型转换的一部分
DSP 现在只支持 8bit 量化的算子,因为量化的算子性能好点。在计算时,可能会把浮点转换长量化值,从而带来精度损失。精度差距比较大的算子已经被禁用了。
HIDL驱动的 Model 有三个重要的接口 supportedOperations 、 prepare 和 execute 。
supportedOperations 使用 HexagonOperationsCheck 中的表来检查是否支持某个算子。
prepare 调用 DSP驱动创建一个新的“图”,该图的处理遵循一般的网络处理流程:
- 向途中添加算子、张量、配置输入输出。DSP 驱动中的算子和张量也以索引形式区别。模型的配置使用了 HexagonOperationsPrepare
- 将图准备好执行——直接调用
hexagon_nn_controller_prepare_fn。 Hexagon NNlib 可能是高通主动参照 Android Neural Networks API 接口设计。
execute 也比较简单,准备好输入输出后就传递给 hexagon_nn_controller_execute_new_fn 。主要的工作花在将 Request 中的内存池信息转换成缓冲区地址信息。
Android NNAPI 的系统性
本文已经介绍了 Android Neural Networks API 的软件架构和实现细节。本节所谓的『系统性』将主要介绍两点:执行过程中各个模块是如何交互的、网络模型在 NDK 层和 HAL 层的联系。
具体运行过程
Android Neural Networks API 的设计引入了跨系统多层的回调,执行逻辑比较复杂,本小节将完整地描述一次推理中软件各部分发生的交互。

上图是整个执行流程的总览。图中以数字为索引标注了模块之间主要的任务执行顺序。如图例,黑色文字和箭头表示常规的流程,蓝色表示模型划分阶段,红色表示模型执行阶段。模型的执行是异步的,各个模块之间有自身的线程,不同的线程用不用的背景颜色区别开。
首先是模型准备阶段(步骤 0 - 1)。这部分比较简单,不再多做介绍。
其次是模型编译阶段(步骤 2 - 4)。这部分已经获得了整个网络的描述,可以根据可选的设备划分执行计划。
再次是模型执行阶段(步骤 5 - 14)。这部分可分为几个子步骤:
- 配置输入输出(步骤 5 - 6)
- 应用启动执行,直到 Android Neural Networks API 准备好(步骤 7 - 8)。这里 ExecutionBuilder 启动执行线程后立即将 Callback 返回给应用。应用使用该 Callback 等待计算结束(步骤 9)
-
asyncStartCompute依次执行每个 Step 使用 StepExecutor 完成步骤- StepExecutor 调用
IDevice::prepareModel让驱动准备模型(步骤 11 ) - 驱动准备好模型(完成优化、编译等工作)后通知 StepExecutor (步骤 12 )
- StepExecutor 调用
IPreparedModel::execute让驱动运行网络(步骤 13 ) - 驱动运行完毕后通知 StepExecutor(步骤 14)
- StepExecutor 调用
- 当所有的 StepExecutor 运行完毕后,
asyncStartCompute线程退出 - 应用得到计算完毕的通知,获得计算结果
目前整个 Android Neural Networks API 仍未开发完善,例如在工作流图中被灰色三角标记出的步骤。其中 asyncPrepare 和 asyncExecute 应该是异步完成的,但目前 HIDL 驱动中都是同步的。被标记的 wait 操作不应当等待驱动准备好模型。
算子与张量之间的关联
可以看到,在各个接口或框架层面,都没有对算子和张量的关联有特别明确的处理——在描述网络时,算子使用的张量用张量在张量表中的索引给出,算子的张量之间也没什么明确的指代。
当我们在描述一个算子的时候,一般是有算子的输入输出张量、参数的张量。而在 Android Neural Networks API 的体系中,描述算子的时候纯粹只是给了个张量的数组,并没有指明各个张量都是什么。这看起来像是,从高层框架(例如 TensorFlow Lite)到底层驱动实现,对于某个特定的算子,大家都遵循特定的约束。只有这样才能合理地解释为什么 Android Neural Networks API 中从未提及参数的各种类型等等。
在 HIDL 描述中,算子的输入排列以注释文档的形式给出,全连接算子的输入输出文档摘录如下。高层的 NDK 头文件接口也有几乎一致的文档。文档详细描述了算子中『第 N 个』张量的属性。
/**
* Denotes a fully (densely) connected layer, which connects all elements
* in the input tensor with each element in the output tensor.
*
* Supported tensor rank: up to 4.
*
* Inputs:
* * 0: A tensor of at least rank 2, specifying the input. If rank is
* greater than 2, then it gets flattened to a 2-D Tensor. The
* (flattened) 2-D Tensor is reshaped (if necessary) to
* [batch_size, input_size], where "input_size" corresponds to the
* number of inputs to the layer, matching the second dimension of
* weights, and "batch_size" is calculated by dividing the number of
* elements by "input_size".
* * 1: A 2-D tensor, specifying the weights, of shape
* [num_units, input_size], where "num_units" corresponds to the number
* of output nodes.
* * 2: A 1-D tensor, of shape [num_units], specifying the bias. For input
* tensor of {@link OperandType::TENSOR_FLOAT32}, the bias should
* also be of {@link OperandType::TENSOR_FLOAT32}. For input tensor
* of {@link OperandType::TENSOR_QUANT8_ASYMM}, the bias should be
* of {@link OperandType::TENSOR_INT32}, with zeroPoint of 0 and
* bias_scale == input_scale * filter_scale.
* * 3: An {@link OperandType::INT32} scalar, and has to be one of the
* {@link FusedActivationFunc} values. Specifies the activation to
* invoke on the result.
*
* Outputs:
* * 0: The output tensor, of shape [batch_size, num_units]. For output
* tensor of {@link OperandType::TENSOR_QUANT8_ASYMM}, the following
* condition must be satisfied:
* output_scale > input_scale * filter_scale.
*/
FULLY_CONNECTED = 9,
在 TensorFlow Lite 中,TensorFlow 的参数序列以一种相对比较复杂的方法转换成顺序排列的。针对每个算子:
首先将输入张量加入到 Android Neural Networks API 中「广义」的输入中
// Add the parameters.
std::vector<uint32_t> augmented_inputs(
node.inputs->data, node.inputs->data + node.inputs->size);
std::vector<uint32_t> augmented_outputs(
node.outputs->data, node.outputs->data + node.outputs->size);
然后使用 add_scalar_int32 等方法将参数加入到 Android Neural Networks API 的模型中
auto add_scalar_int32 = [&nn_model, &augmented_inputs,
&next_id](int value) {
ANeuralNetworksOperandType operand_type{.type = ANEURALNETWORKS_INT32};
CHECK_NN(ANeuralNetworksModel_addOperand(nn_model, &operand_type))
CHECK_NN(ANeuralNetworksModel_setOperandValue(nn_model, next_id, &value,
sizeof(int32_t)))
augmented_inputs.push_back(next_id++);
};
auto add_scalar_float32 = [&nn_model, &augmented_inputs,
&next_id](float value) {
ANeuralNetworksOperandType operand_type{.type = ANEURALNETWORKS_FLOAT32};
CHECK_NN(ANeuralNetworksModel_addOperand(nn_model, &operand_type))
CHECK_NN(ANeuralNetworksModel_setOperandValue(nn_model, next_id, &value,
sizeof(float)))
augmented_inputs.push_back(next_id++);
};
// ...
auto add_fully_connected_params = [&add_scalar_int32](void* data) {
auto builtin = reinterpret_cast<TfLiteFullyConnectedParams*>(data);
add_scalar_int32(builtin->activation);
};
在高通的 DSP 底层驱动 Hexagon NNlib 中,全连接算子的代码片段如下。可以看到,驱动以既定的顺序从算子的若干个输出中取出。
static int fullyconnected_execute(struct nn_node *self, struct nn_graph *nn)
{
const struct tensor *in_tensor = self->inputs[0];
const struct tensor *weight_tensor = self->inputs[1];
const struct tensor *suma_tensor = self->inputs[2];
const struct tensor *bias_tensor = self->inputs[3];
const struct tensor *precip_tensor = self->inputs[4];
struct tensor *out_tensor = self->outputs[0];
struct tensor *out_min_tensor = self->outputs[1];
struct tensor *out_max_tensor = self->outputs[2];
// ...
}
这样一来,通过 Android Neural Networks API 贯穿 NDK 和 HAL 层的统一接口描述,高层深度学习框架和底层硬件驱动所使用的算子和张量的语义描述,是遵循同一套约束的,不需要额外的转换或配置。
总结
在 Android Neural Networks API 中,无论是高层的 NDK 接口还是底层的 HAL 驱动,设计都是非常简洁,功能却非常丰富。这就像 Android Neural Networks API 自身的名称一样,只是充当一个中间型的接口,无意去做优化。
Android Neural Networks API 的目的很简单,作为一个操作系统,将上层框架的模型转换成底层设备上的模型,并运行。上层框架可以更为灵活地拓展功能,提供更强的 runtime 。底层驱动可以专注于计算的优化等工作。这带有一种克制的哲学,避免了“什么都想做,什么都做不好”。这种设计是的上下层都具有一定的灵活性,也比较愿意合作。
在接口设计上,Android Neural Networks API 的设计趋向于极简——对于算子、张量都只定义类型。针对算子、张量接口的操作都是以模型为操作对象。张量与算子的关系比较弱化,算子的参数都是以“文档”形式给出。上层框架和下层驱动需要自行适配。这种设计大大减少了接口数量——只有涉及网络执行流程的几个接口,接口数量不会因为算子类型的增加而增加。
但这种设计方法缺点在于适配过程比较费心,上层框架要将图描述转化成 Android Neural Networks API 这种信息表示方式,底层驱动为了做优化又要将 Android Neural Networks API 的表示转换成自己的描述。不过这种转换在任何尝试抽象出接口的平台都是不可避免的——如果没有统一方便的模型描述方式,整个业界都会在这个问题上付出很大的代价,而 Android Neural Networks API 能在 Android 平台上改善这种处境。
同时,值得注意的是,我们在代码中看到了大量的 TODO ,Android Neural Networks API 还处在迭代过程中。


