我们正在向新域名迁移,3秒后自动跳转
We are migrating to new domain, will redirect in 3 seconds
jackwish.net -----> zhenhuaw.me
虚拟机与二进制翻译技术拾遗
引言
在过去的一年中,因为中美贸易战引发的「卡脖子」问题,计算机系统这种在国内被长期忽视的基础性技术和相关研究开始变得热门。因为相关领域的研究经验,笔者经常会收到一些相关的咨询或邀约。然而近两年笔者的工作已经转向了机器学习系统和高性能计算,对相关的需求不能有太多助益。不过还是可以抽出时间整理一些相关领域公开技术,因此有了这篇文章。此外,针对国内近两年相关领域的发展和舆论,笔者还想结合在虚拟机方面对软件生态的思考谈一谈,不过这个主题可以另开一篇。
本文罗列笔者曾经阅读过的几篇相关领域的经典文献,它们曾经都放在本博客中。不过因为始终是文献阅读,因此后来在研究方向转变后都移除掉了。选择这几篇是因为,尽管学术研究百花齐放,但最后能经得住工程考验商用的技术其实很有限。本文按文献发表时间形成几个小节,并给出 archive.org 的存档——存档是笔者最初阅读论文的笔记(乃至翻译),会有更加详细的介绍。文章最后会总结相关技术,谈一谈笔者的相关经验,并给出一些推荐的资料。
在进入主题前,笔者认为还是有必要简要介绍一些基本的概念,特别是产业的演化。当谈到计算机体系结构之争时,常见的讨论就是 CISC 和 RISC 之争,最后简化为 x86 和 ARM 之争。而在 ISA 层面的黄金年代是上世纪九十年代,涌现了 Alpha、Sparc、MIPS、AIM 等等架构或项目。X86 和 ARM 在本世纪的很多工作都是实现了黄金年代先驱者的思想。当然眼下因深度学习引发的是另一个黄金年代,这一点可参考 Architecture 2030(相关讨论)和 Reboot Computing。而虚拟机技术和动态编译技术很大程度上是各家芯片生产商为了兼容主流系统开发的技术。虽然业态在不断变化,但核心技术还是那些套路。
为什么这些内容很重要?因为这些主题需要处理两种体系结构、两组操作系统下的生态,在包装系统状态一致性的前提下采用编译器技术优化性能。我想没有更复杂的系统了。
Digitial FX!32 技术方案
archive.org 存档 | 原始论文 | 2015-01-23
基于剖析的优化技术依然是虚拟机、编译器和相关领域的关键技术。
Digital 公司的 Alpha 是世界上最快的处理器(当时)。虽然有部分要求高性能的软件被移植到了 Alpha 平台上,但还有很多 X86 软件不能在 Alpha 上使用。因此,Digital 公司开发了可以在 Alpha 平台上以高效率运行 X86 应用的 FX!32 系统。
在不同体系结构上运行应用有两种方法:模拟和二进制翻译。模拟的效率较低但能真正“透明”地运行应用,而二进制翻译效率较高但不能实现透明计算。FX!32 将两者结合起来在业界尚属首次。FX!32 系统由三部分组成:一个支撑透明执行的运行时环境、一个高性能二进制翻译器和将这两种联合起来的服务。
FX!32 是一个基于剖析的软件。第一次运行 x86 应用时完全使用模拟方法,但 FX!32 在软件运行时收集运行相关数据。在应用退出后,FX!32 针对应用中的热点函数使用二进制翻译器将 x86 代码翻译成 Alpha 本地代码,从而替换掉原有的模拟方法。这样,尽管第一次运行会比较慢,后续的运行速度会非常快。这种“剖析-优化”还将一直持续下去。
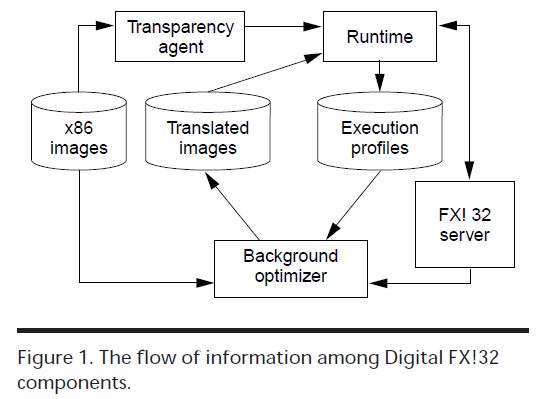
运行时
FX!32的“透明运作”有两层含义:x86应用可以不加修改地运行、x86应用可以和本地应用交互操作。
启动x86应用会触发一个DLL——“透明代理”。“透明代理”可以甄别应用的平台,从而适时启动FX!32运行时环境来执行映像。FX!32的高性能来自于执行Alpha本地代码。模拟和二进制翻译的结合主要由运行时“透明地”将x86代码替换乘Alpha本地代码实现。运行时加载器的功能等同于NT加载器。Alpha NT加载器在尝试执行不同结构的代码时会返回错误以指明被执行的是x86映像。映像加载后,运行时加载器通过将指向映像的指针插入NT使用的表中,从而使得本地Windows NT代码可以区分x86和Alpha映像。接下来,映像进入带有翻译后映像的FX!32数据库。
Win32应用会调用不属于应用自身的函数,比如Win32 API。NT-Alpha使用Alpha调用转换而非x86调用转换来支持这种调用。在管理本地Alpha函数和模拟/翻译代码时需要转换步骤。比如,x86函数通过栈传递参数,而Alpha通过寄存器传递参数。用于完成x86和Alpha之间转换的代码片段称作jacket。Windows NT的大多数系统API都是操作系统的一部分。当NT加载器加载映像时会检测所有符号链接来定位要导入的例程和数据。FX!32运行时通过将入口指向正确的jacket入口来实现类似功能。
翻译优化
FX!32每次运行时加载x86映像时都会查询数据库查看该映像是否已被翻译成Alpha本地代码。这种高效的本地Alpha代码是在之前的模拟后由后台翻译器生成的。在模拟x86映像时,运行时持续收集运行数据,以便后台优化器使用。FX!32的高性能来自于运行时和后台翻译器的良好协作。
FX!32服务用于连接运行时和后台优化器。根据FX!32的默认配置和用户给出的参数,该服务维护着运行剖析数据,并适时地启动后台翻译器。当x86映像卸载后,该服务将新的剖析数据和以往数据合并,如果有新的翻译需求,则将这些需求加到后台翻译器的翻译队列中。
后台翻译器是一个可以生成高效本地Alpha代码的“第三代”基于剖析的二进制翻译器。它在映像执行完毕后被调用,以生成可以在下次运行映像时为运行时所用的本地代码。后台翻译器的工作和输出必须和运行时环境一样透明、健壮。这意味着用户不会意识到翻译器的存在,也无需干预翻译器的运行。为了确保透明、稳健,后台翻译器和运行时共同确保虚拟环境能准确代表x86机器状态,即能在任意观察点完整反应x86寄存器分配、调用返回边界和x86栈的状态。同时,为了达到性能设计目标,翻译器要尽可能地应用针对可预测全局优化的现代编译优化技巧。FX!32在模拟时收集应用的运行数据,然后启动二进制翻译器翻译热点例程。因为翻译器在后台运行,因而可以应用很多高级的优化算法。Digital FX!32是首次将环境模拟、剖析数据生成和二进制翻译结合起来的系统。正因为有剖析数据,不需要实现复杂的代码发现和控制流图算法,翻译器的实现才变得容易,只需要快速简单的查找。也因为剖许数据比控制流图要精确,生成的代码质量也比以往的静态二进制翻译器好,运行效率也高。翻译器使用了很多传统编译器技术:死代码消除、常量传播、公共表达式替换、寄存器重命名、全局寄存器分配、指令调度和很多窥孔优化。
Transmeta 技术方案
Transmeta(全美达)的虚拟机方案软硬件协同设计的经典案例,因此将芯片和软件系统两篇文章合并介绍。Transmeta 最后虽然失败了,但其技术并没有消失,一部分流转到了 nVidia 手中成为了 Project Denver 并最终用在 Nexus 9 平板中。值得一提的是 Linus Torvalds 在 Transmeta 工作了六年。
Crusoe 处理器
archive.org 存档 | 原始论文 | 2015-01-15
Crusoe处理器是Transmeta公司在2000年左右推出的X86兼容系统所依赖的硬件平台。 和传统的纯软件二进制翻译实现的兼容系统不一样,Transmeta通过打造完整的软硬件平台可以高效地模拟X86处理器。 该方案包含两部分:Crusoe处理器和Code Morphing翻译器。 本质上,Crusoe是一个VLIW(超长指令字)处理器,每个时钟周期可以执行多个功能(类似于多发射)。 通过利用VLIW的这种特性,Transmeta重新组织X86翻译后代码,使得多条指令可以“并行”执行,从而提高性能。 Crusoe的主要贡献在于开辟了一种全新的软硬件结合设计方法,使得协同设计真正地能提供一致性平台。(区别于传统的处理器即平台) 基于协同设计的特点,Crusoe方案不光在性能上取得了显著的成果,同时还降低了硬件设计复杂度、硅片面积、功耗等。
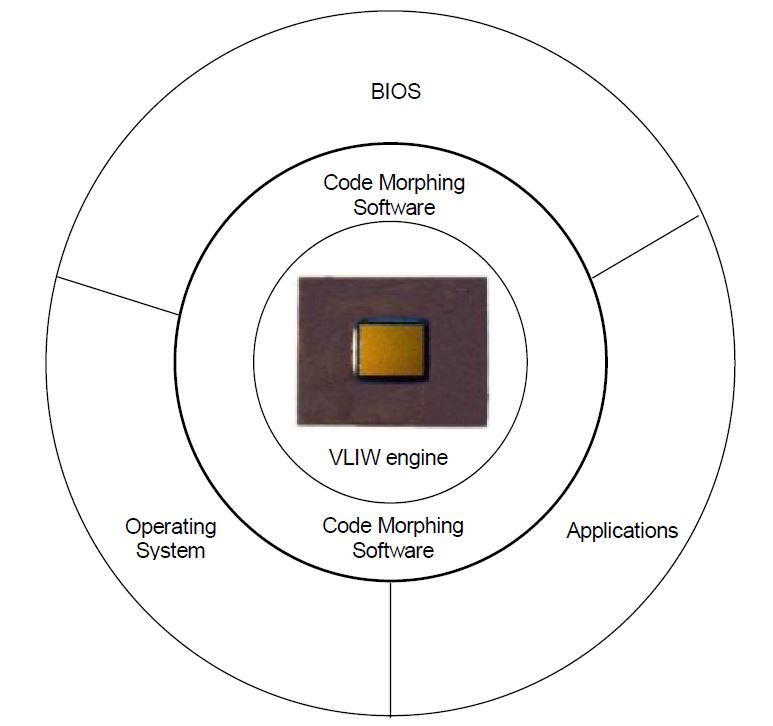
Crusoe方案从某种程度上实现了ISA的虚拟化。通过将X86翻译为Crusoe的VLIW指令,ISA兼容的问题解决了,因为指令翻译是由软件完成的,修改代价较低。 另一方面,硬件复杂度也降低了,Crusoe不再需要复杂的流水线系统,指令优化、流水线维护工作可以交给Code Morphing做。Crusoe处理器就是一个简单的VLIW引擎。同时,对于X86这样带有复杂译码机制的处理器(内部采用微码RSIC结构),重复执行一段代码所带来的译码代价也是很高的。 Code Morphing在翻译X86代码时将翻译后代码存入缓存中,对于同一段代码只需要翻译一次。 这种机制实质上提高了系统性能,还降低了系统功耗。
Crusoe包含三个特殊的硬件支持来提高系统模拟X86的性能。 为了解决复杂代码调度潜在的逻辑问题,Crusoe引入了“影子”处理器状态(相对于“工作”处理器状态)。 每执行一次翻译时,Crusoe复杂维护“影子”状态。 如果这段翻译后代码执行没有触发例外,那么在执行完成之后Crusoe会更新影子状态。 否则,Crusoe会从影子状态中恢复出“最后正确”的处理器状态,进入“保守”执行模式以定位出发例外的指令。对于访存功能,Crusoe维护了一个访存buffer,所有的访存结果都缓存在这里。 当某段翻译后代码执行成功后,buffer中内容会被真正写入存储器; 否则,Crusoe无效掉buffer中所有例外发生后的存储器写操作。
对类似“针对同一个地址‘读-写-读’”重排可能会带来错误,一般的编译器在优化访存相关代码时都非常保守。Crusoe增加了特殊的硬件功能来记录来检测的访存冲突,使得Code Morphing可以对访存指令作激进的代码调度。 同时,这种特性还可以减少“重复读”指令,因为带标记的访存指令对可以放肆执行,系统能确保它们被正确执行。
X86包含很多自修改代码,如果没有特殊机制,自修改代码会导致程序运行逻辑紊乱。 Crusoe增加了特殊的标记位,将翻译后代码区域(如果x86代码地址也被转换了)置为保护态。 这样一来,所有的自修改代码都会导致Code Morphing陷入,从而由特殊的机制来保证翻译后代码也被修改。
CMS 软件系统
archive.org 存档 | 原始论文 | 2016-06-26
Transmeta 的 Crusoe 处理器和 CMS 构造了一种独特的商用体系结构——「内部 ISA」和「外部 ISA」截然不同。由于内部 ISA 不公开给用户,因此可以在每一代产品升级时自由地升级,而外部 ISA (x86) 则是一种通用的兼容传统软件的 ISA 。这种架构使得处理器设计可以变得简单紧凑低功耗。为了提供稳定的具有竞争性的商业产品级别的性能和兼容性,CMS 要解决在传统的二进制翻译和动态优化中被忽略的话题:
- CMS 要支持完整的 x86 体系结构,包括指令、内存映射 IO、寄存器、异常等。
- CMS 是一个系统级别实现,不依赖于任何操作系统的假设,要连 BIOS 都能运行,实现真正的对用户透明的 ISA 兼容系统。
- CMS 要为各种游戏、媒体处理等桌面应用提供可靠稳定的性能,这意味着自修改代码和精确例外必须被完善地处理。值得说明的是,CMS 不是作为一种向新体系结构迁移时的过渡手段,它必须及时解决其他兼容系统可能会忽略的种种问题。
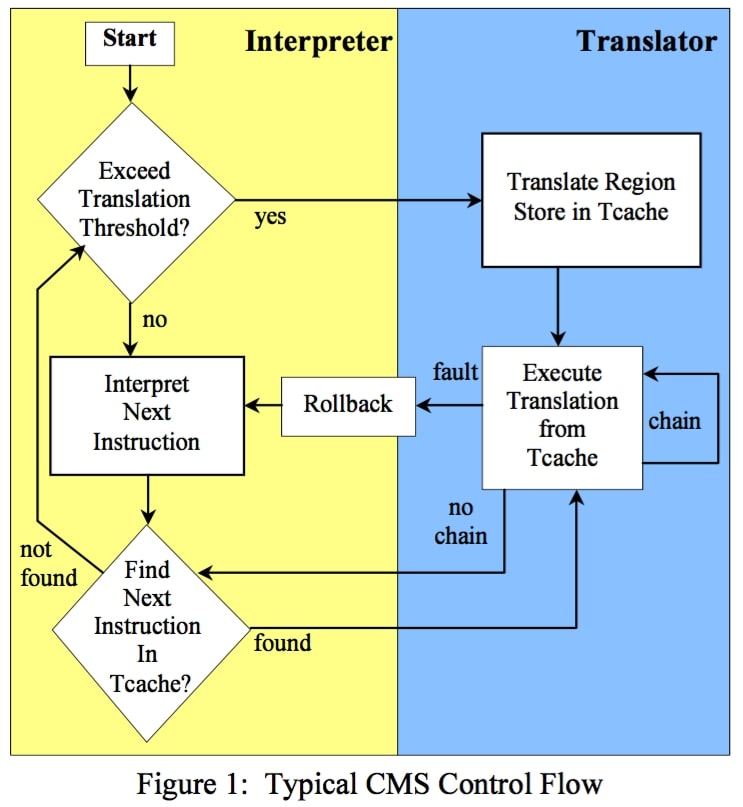
作为协同设计虚拟机(Co-Design Virtual Machind),当推某些特殊类型的推断例外发生时,Crusoe 处理器将例外信息传递给 CMS。CMS 可以像常规操作系统处理例外那样处理推断例外。对于不常见的例外,CMS 用解释器来处理。解释器虽然拥有指令级的精确状态,但性能还是比较低。当这种不常见例外也经常发生时,CMS 会进入「保守翻译」状态,为这部分代码生成更小的 region 但状态更精确的执行翻译。推断和恢复的硬件支持是影子寄存器和存储器缓冲,这在上一小节已经介绍。
对于 x86 这样精确例外且有序执行的 ISA 而言,纯软件模拟的代价是极高的:不能采用激进的翻译策略,要插入大量的「错误恢复」代码,即使不发生例外开销也比较高。不过有了「提交-回滚」硬件支持,CMS 可以非常灵活地调度翻译后代码。CMS 像传统控制推动那样记录信息,也无需生成大量的补偿代码,就能随意调度指令,甚至是分支指令。
自修改代码处理一直是二进制翻译的一大难题,因为要维护翻译缓冲和原始代码的一致性。CMS 早期处理自修改代码就是简单的以页为粒度的写保护,当发生页错误时,丢弃所有受影响的翻译缓存。但页毕竟还是太粗放了,很难处理代码数据混合的页,这种方法的性能非常低。Crusoe 处理器以小于页大小的粒度施行写保护。CMS 在遇到数据代码混合段的写操作时,可以在翻译代码执行前插入「序言」( prologue) 来降低自修改代码带来的开销。另一种解决自修改代码的技术是自检查翻译——在翻译后代码中插入检查 x86 代码是否被修改过的指令。自检查翻译可以融合到常规翻译中,当检查失败时回滚即可。
HP Aries 技术方案
archive.org 存档 | 原始论文 | 2015-03-26
Aries是HP公司于2000年开发的运行于IA-64 (Intel Itanium architecture)平台的PA-RSIC兼容系统。Aries被集成到了HP-UX操作系统中,可以不经用户干预地运行PA-RSIC平台的软件,平滑地实现系统兼容。
Aries系统包含五个部分:启动器(Start-up)、运行时环境(Aries runtime module)、环境模拟器(Environment emulation module)、解释器(Fast interpreter)、动态二进制翻译器(Dynamic translator),如下图所示。
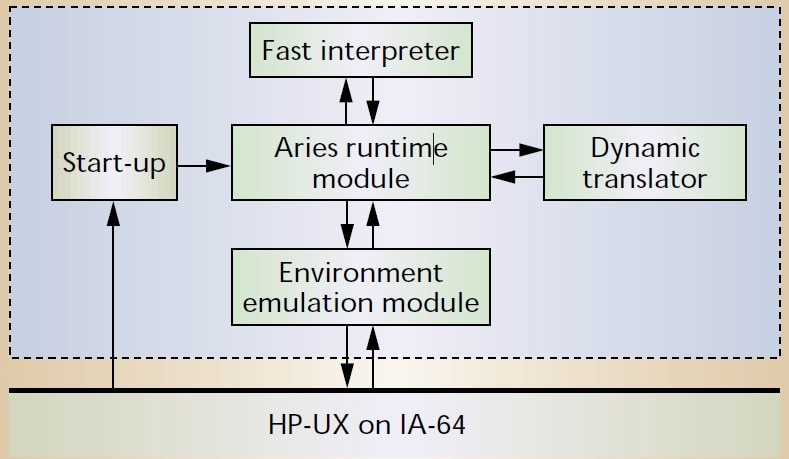
Aries启动器和HP-UX操作系统紧密结合,检测用户程序属于PA-RSIC平台还是IA-64平台。如果是PA-RSIC平台,Aries启动器将控制权交给Aries运行时环境。如果是IA-64平台的程序,直接执行该程序。
Aries运行时环境负责管理整个客户机程序的运行过程。在最开始,Aries用解释器模拟执行客户机程序,动态地收集程序运行的统计信息,在统计数据达到阈值后启动翻译器将客户机代码翻译成宿主机本地代码。动态二进制翻译器在翻译代码时以基本块为单位,并将翻译后代码存储在代码缓存中。客户机程序退出时Aries自动清空翻译后代码缓存。Aries解释器主要用于模拟很少执行或难以翻译的客户机代码。Aries解释器将PA-RSIC的浮点寄存器映射到了IA-64上,避免了大量潜在的寄存器存取操作。
Aries动态二进制翻译器采用了死代码消除、地址混杂去冗余、存储器引用去冗余、基本块块间直接跳转等优化技术。Aries翻译器实现了自修改代码支持。自修改代码是指程序在运行过程中修改自身的代码。Aries翻译器检测到自修改代码时会清除整个翻译后代码缓存以确保模拟的正确性。
Aries环境模拟器实现了客户机系统调用的相关支持,包含两种类型:系统调用直接映射和系统调用模拟。Aries平台的客户机和宿主机都是HP-UX操作系统,大部分系统调用可以通过Aries环境模拟器直接映射。不能映射的系统调用由Aries环境模拟器负责模拟。
Intel IA-32 EL 技术方案
archive.org 存档 | 原始论文 | 2016-06-24
安腾系统是 Intel 公司的新型高性能处理器平台,完全抛弃了 IA-32(x86)架构的历史包袱。但这带来的负面效果就是安腾系统不能运行 IA-32 指令。目前的解决方案是在安腾处理器中增加额外的硬件电路,从而实现IA32 指令兼容。而 IA-32 EL 是针对安腾处理器和 IA32 指令现状设计的一套纯软件系统,能加速安腾平台的 IA32 应用软件。IA-32 EL 主要有三个特点:两阶段翻译系统,第一次翻译时收集大量的程序运行信息,这些信息用于在第二次翻译时对指令进行优化;一个独立于操作系统的翻译器,其巧妙的设计使得 IA-32 EL 的翻译器能支持多个操作系统;用于精确例外处理的特殊机制。
从概念上讲,IA-32EL 是一个进程级的翻译器,和被翻译的进程共享一套地址空间和系统权限,原进程的映像和数据和它们在 IA-32 平台上运行一致。IA-32 EL 被分为两部分:核心模块 BTGeneric、系统兼容模块 BTLib,从而有效地支持多个操作系统。其中,BTLib 用于为 BTGeneric 提供操作系统的服务,如内存分配等,两者通过精确定义的 API 协作。
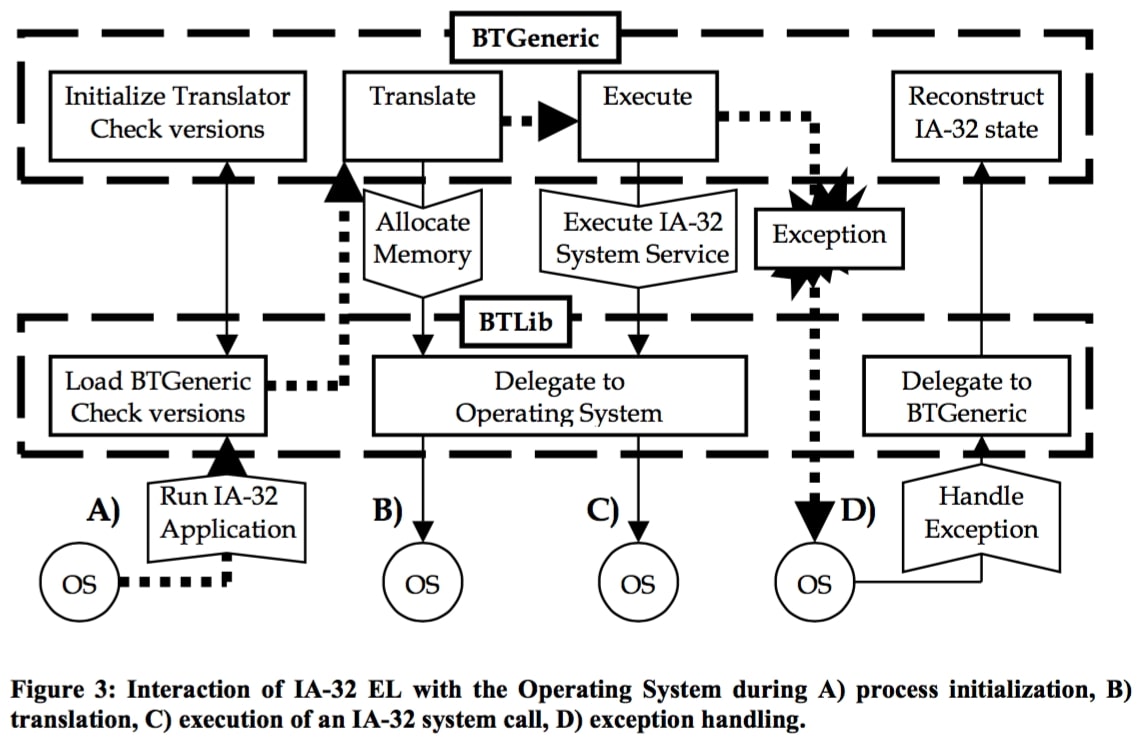
翻译系统
一般的翻译器都没有所谓的「冷代码翻译」阶段,而是直接解释执行(interpretation)。IA-32 EL 的冷代码翻译使用附近的代码块信息来优化当前代码块的翻译。冷代码翻译阶段使用了预先准备的翻译模版来加速翻译和提高翻译效果。这些手工编写的翻译模版充分了利用安腾平台的特性。执行翻译后冷代码时会统计基本块执行次数、跳转边执行次数和非对齐检测。相比于常规的解释器信息统计,冷代码块的统计更加精确,代价也低。
在翻译后冷代码执行过程中,当一个基本块的执行次数达到阈值,便将其注册为热代码预备块。注册过程由翻译器中的特殊函数完成,插在基本块中的阈值检测函数负责转向该函数。当已注册的块数达到一定数量,或者一个块被注册了两次,即刻启动热代码翻译。热代码翻译首先评估多个代码块,并将它们重新组合、分割。大约有 5-10% 的冷代码块回达到注册阈值。 热代码翻译分为多个步骤:
- 翻译器选择多个基本块来组成一个超块(hyperblock),又称踪迹——一段包含一个入口和多个出口的代码。
- 冷代码会被转换成一种目标机器指令的中间表示。
- 翻译器扫描中间代码表来建立一个数据依赖关系图执行流图优化度中间代码。
- 紧接着,调度器将指令分配成热块。
- 翻译器还生产可用于处理例外和中断的恢复信息。
- 最后编码后的块及其信息被放到翻译缓冲中,并和其他的代码连接起来。
运行时
IA-32 EL 在 64 位系统上以应用的虚拟地址空间和特权级运行,代替操作系统为 IA-32 应用提供透明的运行时环境。IA-32 EL 要使用操作系统的诸多服务,如内存分配、同步堆等;也要执行 IA-32 应用发出的系统调用、信号处理、例外等系统通知。
状态恢复/精确例外是二进制翻译和虚拟机的一大难题,对于 IA-32 EL 这样高度优化的软件而言就更为艰巨。这主要是因为一个源指令会被翻译为多个目标指令,而例外未必发生在最后一条目标指令。高性能的二进制翻译软件大多采用激进的代码调度算法,源机器和目标机器之间的状态一致性难以得到保证。
冷代码翻译要求任何例外发生时 IA-32 状态都能正确地恢复。IA-32 EL 使用「懒惰更新」IA-32 状态来完成,即当(潜在的可能会发生错误的)翻译后指令全部执行完毕后才更新 IA-32 的状态。热代码翻译的状态恢复就难多了。IA-32 EL 使用「提交点」( commit point )来解决激进代码重排带来的精确例外问题。提交点是一种让翻译器能生成一致性 IA-32 状态的「屏障」:每个提交点可能涵盖了多个故障点(faulty points);限制属于不同提交点的指令重排;和冷代码类似,对于每次代码翻译,当最后一个故障点之后才更新 IA-32 状态。
IA-32 平台的非对其访存开销不高,因而被应用程序广泛使用。而安腾作为现代体系结构,硬件是不支持非对其访存的,软件模拟的开销往往高达上千个时钟周期。因此在模拟 IA-32 时,非对其访存是个重要问题( FX!32 系统也面临这样的问题)。IA-32 EL 对非对其访存的处理分为三个阶段:冷代码翻译阶段插入简单的剖析仪表;重新翻译的代码带有非对其检测与避免功能;在热代码翻译阶段,每个冷代码块的信息都会被手机起来,每条「非对其访存指令」都会使用如上述的检测与避免代码。
KVM - Linux 虚拟机监视器
archive.org 存档 | 原始论文 | 2016-07-03
前文说列举的都是基于二进制翻译技术的虚拟机兼容系统,着力点在兼容。随着指令集之争渐熄,同体系结构虚拟化成为了虚拟机发展的重要主题,这里仅列举 KVM ,其他的亦可参见相关资料。
x86 架构新增的虚拟化拓展使得在该平台上开发虚拟机监视器(Virtual Machine Monitor, VMM)更加容易了。kvm (Kernel-based Virtual Machine) 是一个新的,能让多个虚拟机像 Linux 进程一样无缝运行的 Linux 子系统。
众所周知,x86 的硬件使得它很难实现虚拟化,但 Intel 和 AMD 都为 x86 架构增加了相似的虚拟化拓展:新增客户机工作模式,处理器可以切换到客户机模式;当在客户机模式切换时,硬件会自动切换受影响的控制寄存器、段寄存器、指令指针;当客户机退出(退回宿主机)时,硬件会报告原因,这样软件就能才去恰当的操作。
kvm 虚拟机在打开 /dev/kvm 时创建。客户机有自己的内存空间,独立于创建它的用户进程;不能自己调度虚拟 CPU。用户可以使用一系列 ioctl() 操作来操作虚拟机:创建新虚拟机、为某个虚拟机分配内存、读写虚拟 CPU 寄存器、向某个虚拟 CPU 注入中断、运行某个虚拟 CPU。运行某个虚拟 CPU 需要精心设计。Linux 在「内核模式」(kernel mode) 和「用户模式」(user mode) 的基础上,新增了「客户机模式」(guest mode) 来支持虚拟机。执行客户机要经过一个三层循环(如下图)。
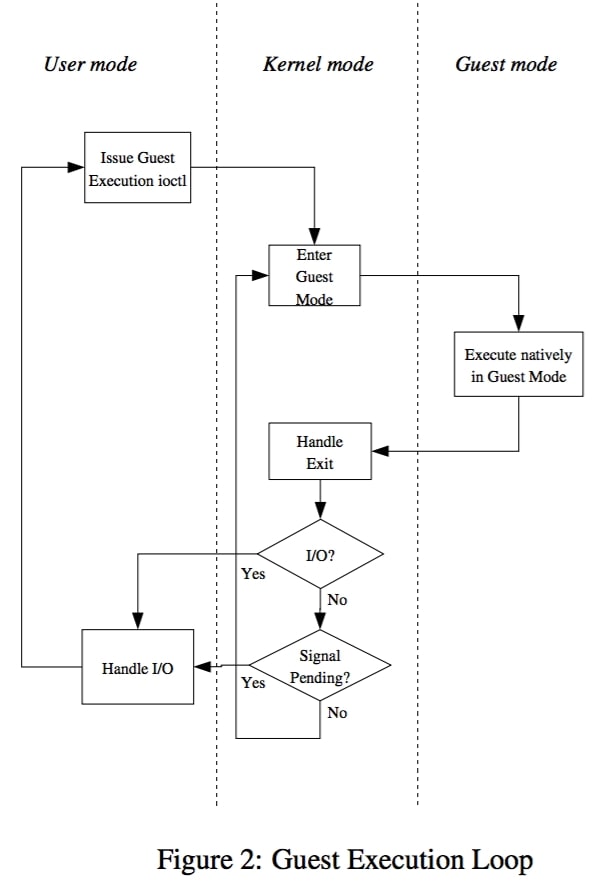
在虚拟机中,MMU (Memory Management Unit) 虚拟化的主要问题是 GVA (Guest Virtual Address) -> HVA (Host Virtual Address) 地址转换。这个过程是 GVA -> GPA -> HVA -> HPA,更详细的介绍可以参考A Dual-TLB Method for MIPS Heterogeneous Virtualization 。
x86 的虚拟化拓展中,MMU 只负责转换 GVA -> GHA 。传统的解决方法都是再生成一个影子页表来保存 GVA -> HPA 地址映射,并模拟原客户机页表和硬件的交互。影子页表在地址转换错误发生时被不断填充新表项。kvm 用「写保护」解决客户机更新页表没有陷入这一问题。
软件使用「编程 IO 」(programmed I/O, pio)、「内存映射 IO 」(memory-mapped I/O, mmio)和硬件设备通信。硬件也可以发起中断来请求软件服务。当内存映射 IO 的页被访问时,kvm 的 MMU 不创建影子页表的地址转换;而是由 x86 模拟器执行例外指令。kvm 的 IO 虚拟化在用户空间完成。所有的编程 IO 和内存映射 IO 访问都被导入用户空间,用设备模型来模拟他们的行为(有时会触发真正的 IO)。kvm 为用户空间增加了中断注入装置,来检查客户机是否接受中断,并适时诸如中断。这样以来,kvm 可以模拟 x86 系统复杂 IO 设备。
虚拟化可以让虚拟机在迁移的过程中一直保持运行状态。但迁移过程中,客户机的内存扔在被读写,那么最早被拷贝的内存可能「过期」了。kvm 使用「脏页记录」(dirty page log) 来解决这一问题——用户空间可以访问一个记录了上次拷贝后被修改的页的位图。最开始时,所有的客户机页都是只读的,当写操作发生时,kvm 能追踪是哪些页被修改了。不间断迁移会持续进行,直到没有任何脏页尚未拷贝。
漫谈
本文列举了笔者认为虚拟机与二进制翻译技术结合的几个经典案例。虚拟机大家都是司空见惯的,如 Java 虚拟机、VMware、Qemu 等。但二进制翻译着实是比较冷门的技术。一般而言,我会说动态编译而不是二进制翻译,因为两者的基本区别其实只是「前端」不同而已。从上面的几个经典二进制翻译系统也可以看到,翻译器的核心技术和当今的动态编译技术并无不同,运行时技术的方方面面也和操作系统非常相似。一言以蔽之,相关领域的技术解决的主要方法论是,精确地维持客户机和真机运行的一致性。只要能保证一致性,其他的随便玩。
笔者接触相关领域主要是研究生阶段在中国科学院计算技术研究所(简称计算所)的学习生涯。计算所号称「中国计算机产业的摇篮」,除了科研学术产出外,还孵化出了联想、曙光、龙芯、寒武纪等知名企业。我所在的微处理器实验室(即龙芯)为了解决不同 ISA 间软件兼容的问题,长期在基于二进制翻译技术的虚拟机领域持续投入。我在校的研究工作参与了一项软硬件结合优化技术,相关工作可以参考 A Dual-TLB Method for MIPS Heterogeneous Virtualization 。
离开学校后我加入了 Intel 亚太研发中心的 BiTS (Binary Translation Software,后更名为 Machine Learning and Translation) 项目组,参与了 Houdini 项目。Houdini 是 Intel 研发的用于 Android 设备的虚拟机,它使得基于 ARM 的 Android 应用能在 Intel 设备(如 Nexus Player 和 Chromebook)上流畅运行。作为 Intel + Android 的核心技术,Houdini 已广泛应用于移动设备、桌面和云计算等领域。NativeBridge 是 Intel 和 Google 一道设计的在 Android 中支持多种 ISA 的平台型技术(听说龙芯也在基于 NativeBridge 做相关工作)。
在此也向对 Houdini 有兴趣的各界人士说明一下,Houdini 是 Intel 的保密项目,笔者不负责解答相关问题。如有任何技术或商业需求,请直接联系 Intel 的支持人员。
加入 Intel 不久,我得到一个结论——以二进制翻译为核心的虚拟机技术,其生就是为了死。因为二进制翻译主要用于兼容其他的 ISA 平台,那么如果新的 ISA 成功构建出生态,那么相关项目就不再需要;如果新的 ISA 没有成功,那么相关项目也自然会取消。悲壮!上面列举的二进制翻译系统最后都随着 ISA 失败了。当然,成功的项目也有,例如 Apple 推动 MacBook 从 PowerPC 切换到 x86 时使用的 Rosetta 。笔者认为该项目能成功的至关重要的因素是 Apple 对其平台的生态有着无以伦比的控制力。
虽然项目的成功与否不是技术能决定的,但技术依然长存,最多换个名字。
最后列出一个相关的不完整的文献列表,主要涵盖虚拟机和二进制翻译。如果需要概述性的材料,可以参考 James E. Smith 和 Ravi Nair 的经典著作 Virtual Machines .
Binary Translation
DIGITAL FX!32 Combining Emulation and Binary Translation
Dynamic and Transparent Binary Translation
Addressing the Challenges of DBT for the ARM Architecture
Binary Translation Static, Dynamic, Retarget able
DAISY Dynamic Compilation for 100% Architectural Compatibility
DARCO- Infrastructure for Research on HW SW co-designed Virtual Machines
DIGITAL FX!32 - Combining Emulation and Binary Translation
DIGITAL FX!32 Running 32-Bit x86 Applications on Alpha NT
Disco- running commodity operating systems on scalable multiprocessors
Ditzel_Experience_with_Dynamic_BT_sm
Dynamic Binary Translation Specialized for Embedded Systems
Dynamic Binary Translation and Optimization report
Dynamic Binary Translation and Optimization slides
Dynamo- A Transparent Dynamic Optimization System
Embra- Fast and Flexible Machine Simulation
FX!32 A Profile-Directed Binary Translator
HP ARIES Technical overview, references and success stories
IA-32 Execution Layer a two-phase dynamic translator designed to support IA-32 applications on Itanium®-based systems
International QEMU Users' Forum 2011
Linear Scan Register Allocation
PA-RISC to IA-64 transparent execution, no recompilation
Porting QEMU to Plan 9- QEMU Internals and Port Strategy
QEMU internals
QEMU, a Fast and Portable Dynamic Translator
SPIRE- Improving Dynamic Binary Translation through
The Transmeta Code Morphing Software Using Speculation, Recovery, and Adaptive Retranslation to Address Real-Life Challenges
The technology behind Crusoe processors_aklaiber_19jan00
crusoe-mobilecomputing
A Performance Comparison of Container-based Virtualization Systems for MapReduce Clusters
AMD-V™ Nested Paging
Achieving High Performance via Co-Designed Virtual Machines - Smith
An Updated Performance Comparison of Virtual Machines and Linux Containers
Comparisons of memory virtualization solutions for architectures with software-managed TLBs
Efficient, transparent, and comprehensive runtime code manipulation
Graphic Acceleration Mechanism for Multiple Desktop System Based on Virtualization Technology
Hardware accelerated Virtualization in the ARM Cortex™ Processors
Hardware-assisted Virtualization EPT - L04_VTx.pptx
Improving virtualization in the presence of software managed translation lookaside buffers
Intel virtualization technology
Intel_Nehalem_Processor
Intel® Virtualization Technology for Directed IO
KVM, OpenVZ and Linux Containers - Performance Comparison of Virtualization for Web Conferencing Systems
Large Language Models in Machine Translation
Linux Containers -Why They are in Your Future and What Has to Happen First
Linux Support for ARM LPAE
NPC 2010 - Network and Parallel Computing
Optimizing Xen VMM Based on Intel® Virtualization Technology
PSVM- Parallelizing Support Vector Machines on Distributed Computers
Performance Analysis of Container-based Hadoop Cluster - OpenVZ and LXC
Performance Evaluation of AMD RVI Hardware Assist - VMware
Performance Evaluation of Container-based Virtualization for High Performance Computing Environments
Performance Evaluation of Intel EPT Hardware Assist - VMware
VMware’s Virtual Platform
Virtual Machine Monitors Current Technology and Future Trends
Xen and the Art of Virtualization
kvm- the Linux Virtual Machine Monitor


