我们正在向新域名迁移,3秒后自动跳转
We are migrating to new domain, will redirect in 3 seconds
jackwish.net -----> zhenhuaw.me
Convert TensorFlow Lite Models to ONNX
Open Neural Network Exchange (ONNX) aims to bridge deep learning frameworks together. TF2ONNX was built to translate TensorFlow models to ONNX, therefore other deep learning systems can benefit from TensorFlow functionality. However, TF2ONNX currently doesn’t support quantization. And there is some models released in TensorFlow Lite (TFLite) format only. This article introduces TFLite2ONNX which converts TFLite models to ONNX with quantization semantic translation enabled.
Introduction
ONNX, created by Facebook and Microsoft originally, is an open format built to represent machine learning models and has developed into a community-driven organization.
 Figure 1: The ONNX Vision
Figure 1: The ONNX Vision
TF2ONNX was built to convert TensorFlow models to ONNX to bring TensorFlow trained models to systems that support ONNX.
TF2ONNX does have some limitations (as of v1.5.5, when we started to build TFLite2ONNX) such as no support for TensorFlow 2.0 nor quantization. The effort of converting volatile TensorFlow model representation to ONNX is significant. And, as quantization plays a more and more important role in deep learning deployment, lacking such support is a drawback.
On the other hand, the model representation of TFLite is relatively stable, and the officially maintained model converter of TensorFlow and TFLite is robust enough. The converter simplifies the TensorFlow models by graph transformations including Batch Normalization folding and activation function fusion. The FakeQuantWithMinMaxVars nodes, which are generated during TensorFlow Quantization-aware Training (QAT), can also be handled.
Besides, some models release only TFLite format ones despite they are built by TensorFlow, e.g. Google MediaPipe. For such models, there is no chance to leverage them in the ONNX ecosystem.
TFLite2ONNX is created to convert TFLite models to ONNX. As of v0.3, TFLite2ONNX is compatible with TensorFlow 2.0 (thanks to TFLite converter) and quantization conversion. This article introduces the story and implementation of TFLite2ONNX that is used to close the semantic gap between TFLite and ONNX model representation.
Data Layout Semantic Conversion
The most obvious gap is the data layout issue - the TFLite model is NHWC format while ONNX is NCHW, which is named as layout semantic divergence in this article.
The Problem and TF2ONNX
The data layout format of TFLite has not been mentioned in either the document or the model representation but in the implicit agreement of the TFLite converter (the TensorFlow model needs to be NHWC) and the kernels.
On the contrary, ONNX explicitly declares that it uses NCHW in both operator representation and document (which is generated from operator representation).
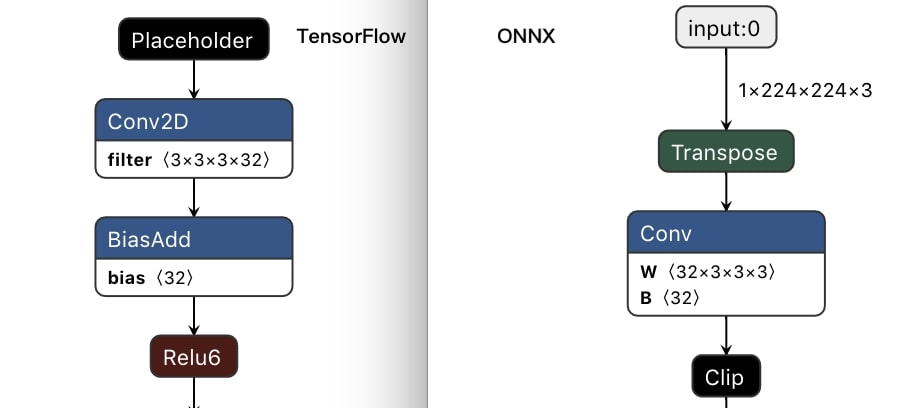 Figure 2: Data layout handling of TF2ONNX - MobileNetV2 example
Figure 2: Data layout handling of TF2ONNX - MobileNetV2 example
TF2ONNX converts the internal operators and tensors into the NCHW data layout, and lets the user define whether do they need the inputs and outputs of the graph to be NHWC data layout by --inputs-as-nchw. Transpose operators are inserted to bridge NHWC and NCHW subgraphs if NCHW is not specified, which is by default. Figure 2 above is an example that we convert the MobileNetV2 TensorFlow model to ONNX by using TF2ONNX. (More description of TF2ONNX’s handling of data layout can be found at the GitHub issue.)
During the development of TFLite2ONNX, we tried two approaches:
-
Transpose based approach - enabled in
v0.1and dropped inv0.3. -
Propagation based approach - introduced and default since
v0.2.
Transpose based Approach
Regarding layout semantic divergence, one fact is, some operators have implicit data layout, e.g. Conv; while others don’t, e.g. Add.
The transpose based approach in TFLite2ONNX inserts a transpose pattern where the operator has layout semantic divergence. The transpose pattern is a Transpose operator bridges source layout (TFLite) and target layout (ONNX).
For example, the TFLite pattern \(\left<Data_{nhwc}\right> \rightarrow [Conv]\) is converted to \(\left<Data_{nhwc}\right> \rightarrow [Transpose] \rightarrow \left<Data_{nchw}\right> \rightarrow [Conv]\). (In this article, \(\left<TensorName\right>\) and \([Operator]\) denotes a tensor and an operator respectively.) Figure 3 is an example of converting the first Conv of MobileNetV2.
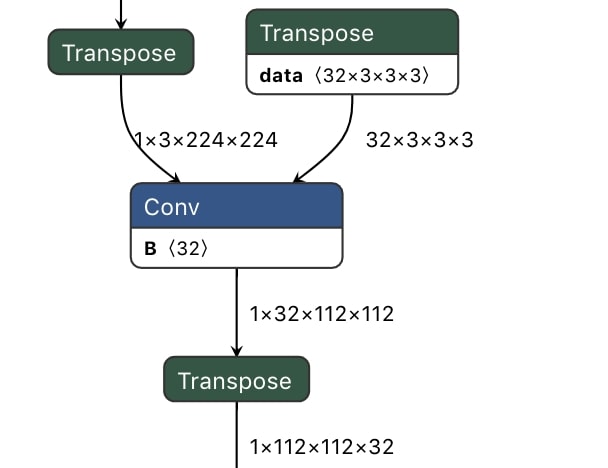 Figure 3: ONNX model converted by transpose based approach of TFLite2ONNX
Figure 3: ONNX model converted by transpose based approach of TFLite2ONNX
With this approach, we only need to process a limited set of operators such as Conv and Pooling. All other operators and tensor conversion are trivial - no layout semantic divergence.
Propagation based Approach
Though the transpose based approach can handle layout semantic divergence, too many operators and tensors (i.e. transpose pattern) are added, therefore the generated ONNX model is too large and complicated. The propagation based approach is introduced to resolve this by propagating the layout semantic divergence across the graph, in which way the transpose pattern is not needed.
By default (for most cases), given a graph, some of the tensors have implicit layout semantic, e.g. tensors that are connected to Conv directly, while others are not, e.g. Abs and Add. The later ones are transparent to layout, where transparent means all of the tensors that connected to the operator mush have the same layout semantic or don’t hold such semantic.
So when an operator that is transparent to layout is connected to an operator that has implicit layout tensors, then all tensors of the transparent operator have the same layout semantic as the tensor that connecting these two operators, named as propagation.
For example, when converting the TFLite graph (omitted kernel and bias) \(\left< A_{nhwc} \right> \rightarrow [Conv] \rightarrow \left< B_{nhwc} \right> \rightarrow [Abs] \rightarrow \left< C_{?} \right>\) to ONNX, tensor \(\left< A_{nhwc} \right>\) becomes \(\left< A_{nchw} \right>\) and \(\left< B_{nhwc} \right>\) becomes \(\left< B_{nchw} \right>\). Hence, the output \(\left< C \right>\) of \([Abs]\) should have the same format as the input \(\left< B \right>\). Propagation based approach propagates the conversion from \(\left< B \right>\) to \(\left< C \right>\). Therefore we have the ONNX graph \(\left< A_{nchw} \right> \rightarrow [Conv] \rightarrow \left< B_{nchw} \right> \rightarrow [Abs] \rightarrow \left< C_{nchw} \right>\), where no additional operators nor tensors are introduced.
During layout propagation, the layout transformation permutes the shape of tensors if they are activations, i.e. value info in ONNX, and transposes the data of weights in addition, i.e. initializer in ONNX.
In practice, operators are categorized into four (as marked in Figure 5):
-
Implicit: operators have layout semantic divergence, e.g.
Conv. They are the source of layout semantic divergence. -
Transparent: operators that are insensitive to layout, e.g.
Abs. If any tensor has layout semantic divergence, propagate it to all tensors that are connected to such operators. -
Attribute: operators that can propagate layout semantic divergence just like Transparent, but have layout sensitive attributes that need special handling, e.g. attribute
axisofConcat. An additional pass after propagation to adjust these attributes is required. -
Terminate: operators that don’t have and cannot propagate layout semantic divergence, e.g.
Reshape. The propagation across the graph terminates at such operators.
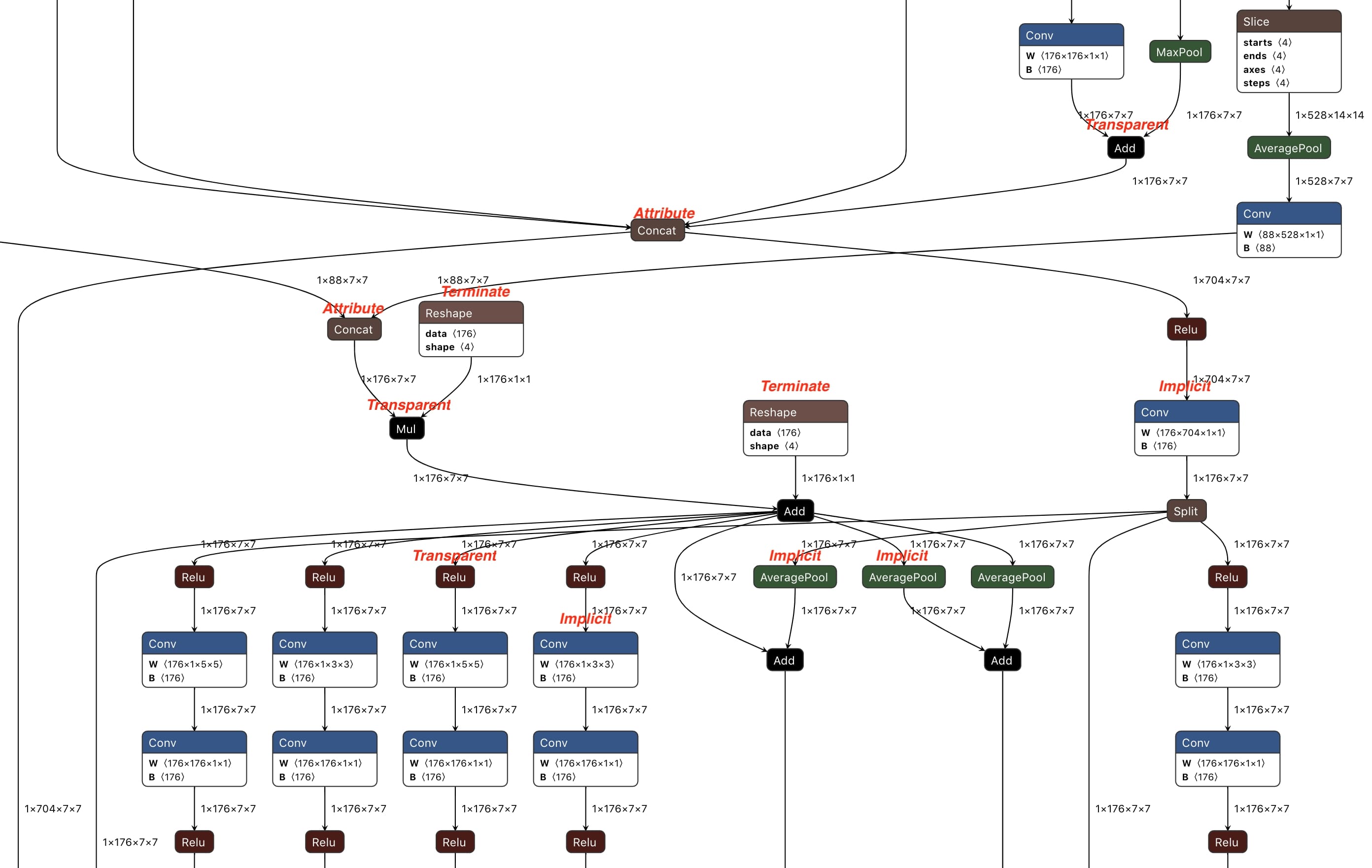 Figure 5: Part of the ONNX model generated by propagation based approach of TFLite2ONNX
Figure 5: Part of the ONNX model generated by propagation based approach of TFLite2ONNX
When propagating layout semantic divergence across the graph, for a particular operator: if it is Transparent or Attribute, propagate layout semantic divergence among its tensors; if it is Implicit or Terminate, terminates the propagation in this direction. Figure 5 is part of the ONNX model generated by propagation based approach from the NASNet TFLite model.
Explicit Layout and Broadcast of Propagation
With propagation based approach, the converted ONNX model includes zero effort to handle layout semantic divergence, i.e. no additional operators or tensors are introduced.
However, sometimes there could be incompatible layouts. Consider Reshape, which is Terminate, as below. If \(\left< A \right>\) is propagated while other tensors are not, the output layout could be unexpected as the user may assume the dimensions of \(\left< B \right>\) has something to do with \(\left< A \right>\). (Transpose based approach doesn’t have this issue as its layout is TFLite style at the model level, layout semantic divergence is handled inside the \([Transpose] \rightarrow [OP] \rightarrow [Transpose]\) pattern.)
Explicit layout is introduced to handle such a scenario. Users can feed a mapping of \(\{Tensor\ name : tuple(TFLite\ layout, ONNX\ layout)\}\) that describes the data layout of TFLite and ONNX to TFLite2ONNX. And, it’s flexible for the user to define the layout conversion for non-_Transparent_ operators. For example, we have performed the NHWC to NCHW layout conversion for a TFLite graph that has only an Add operator.
Another problem is the broadcast of binary operators such as Add (see this issue for more). Taking the example below, in which tensor \(\left< B \right>\) needs to be broadcasted. If \(\left< A \right>\) is converted from NHWC to NCHW, i.e. \(\left< A_{(2 \times 5 \times 3 \times 4)} \right>\), \(\left< B \right>\) is no longer broadcastable in ONNX. Even worse, the layout semantic divergence will fail when propagated to \(\left< B \right>\) as \(\left< A \right>\) and \(\left< B \right>\) have different dimensions.
To manage broadcasting in the ONNX model, tflite2onnx introduces the Reshape pattern. Any tensors like \(\left< B \right>\) are reshaped to extend (inserting \(1\)) their dimensions to be equal with the other, such that propagation and broadcasting can correctly do their jobs. The example of the intermediate graph before propagation is as below.
Quantization Semantic Conversion
TensorFlow stack is the first to provide production-ready quantization support. By converting quantized TFLite models to ONNX, we can bring the quantization capability to more systems. (If the data type in this section confuses you, check more in the discussion when we brought quantization to TVM.)
The Problem and TF2ONNX
TensorFlow and TFLite provide many solutions for quantization: spec, post-training, and quantization-aware training. All these techniques contribute to TFLite models of which tensors are quantized - uint8 for the most case which is enabled by quantized version operators in TFLite runtime. In this article, the uint8 data and scale and zero point of a quantized tensor are denoted as quantization semantic in general.
On the other hand, quantization support in ONNX has two aspects (wiki):
- Quantized operators that accept low precision integer tensors (
uint8orint8).-
QLinearConvandQLinearMatMulgenerate low precision output, similar to TFLite’s quantizedConv. -
ConvIntegerandMatMulIntegergenerateint32output, which can be requantized to low precision.
-
-
QuantizeLinearandDequantizeLinearoperators that convert high precision (floatandint32) to and from low precision respectively.
The semantic gap between TensorFlow and ONNX is significant.
As the quantization representation is designed for TFLite, the TensorFlow graph has limited support of quantization. Therefore, TF2ONNX doesn’t provide quantization support is straightforward.
Using Quantized Operators
In the initial design of TFLite2ONNX, an quantized TFLite operator is converted to quantized ONNX operator, if it has a peer e.g. QLinearConv; and converted back to float otherwise.
As only Conv and MatMul has quantized version operator in ONNX, an end to end quantized ONNX model is impossible. Therefore, the quantized ONNX operator needs to be closed by quantize and dequantize operators.
For example, given the TFLite graph above, in which \(q\) denotes the tensor or operator is quantized, quantize and dequantize operators are inserted around \([Conv]\), and tensors and operators elsewhere are converted back to float, as below.
\[\left. \begin{aligned} \left< A_{float} \right> \\ \left< B_{float} \right> \\ \end{aligned} \right\} \rightarrow [Add] \rightarrow \left< C_{float} \right> \rightarrow [QuantizeLinear] \rightarrow \left< D_{uint8} \right> \rightarrow [QLinearConv] \rightarrow \left< E_{uint8} \right> \rightarrow [DequantizeLinear] \rightarrow \left< F_{float} \right>\]For models that are mainly composed of Conv, e.g. MobileNetV1 (we do have tried to convert such), this is not very significant. But for most other models, Conv and MatMul take a small part regarding the count of operators, we will have too many new operators and tensors in the resulted ONNX graph.
What’s more, like many other deep learning systems, ONNX tensor representation doesn’t carry quantization semantic. I.e. a low precision uint8 tensor is raw uint8 data just like numpy - no zero point nor scale description. For the tensors that converted back to float, the quantization semantic of them has lost - we do not benefit much from mechanisms like quantization-aware training.
Maintaining Quantization Information
Instead of using quantized operators, TFLite2ONNX maintains quantization semantic in the ONNX model by inserting the quantization pattern.
\[[OP] \rightarrow \left< T_{f} \right> \rightarrow [Quantize] \rightarrow \left\{ \begin{aligned} \left< T_q \right> \\ \left< T_{zero\_point} \right> \\ \left< T_{scale} \right> \\ \end{aligned} \right\} \rightarrow [Dequantize] \rightarrow \left< T'_{f} \right> \rightarrow [OP]\]In practice, tflite2onnx generates ONNX graph above from TFLite graph \([OP_q] \rightarrow \left< T_{q} \right> \rightarrow [OP_q]\).
If the original TFLite model has \(O\) operators and \(T\) tensors, the generated may have \(O+2T\) operators and \(3T\) tensors. Yes, this mechanism adds even more tensors, but the scale and zero point semantic are maintained in the ONNX model. Figure 6 is an example of converting the quantized TFLite Conv model to ONNX.
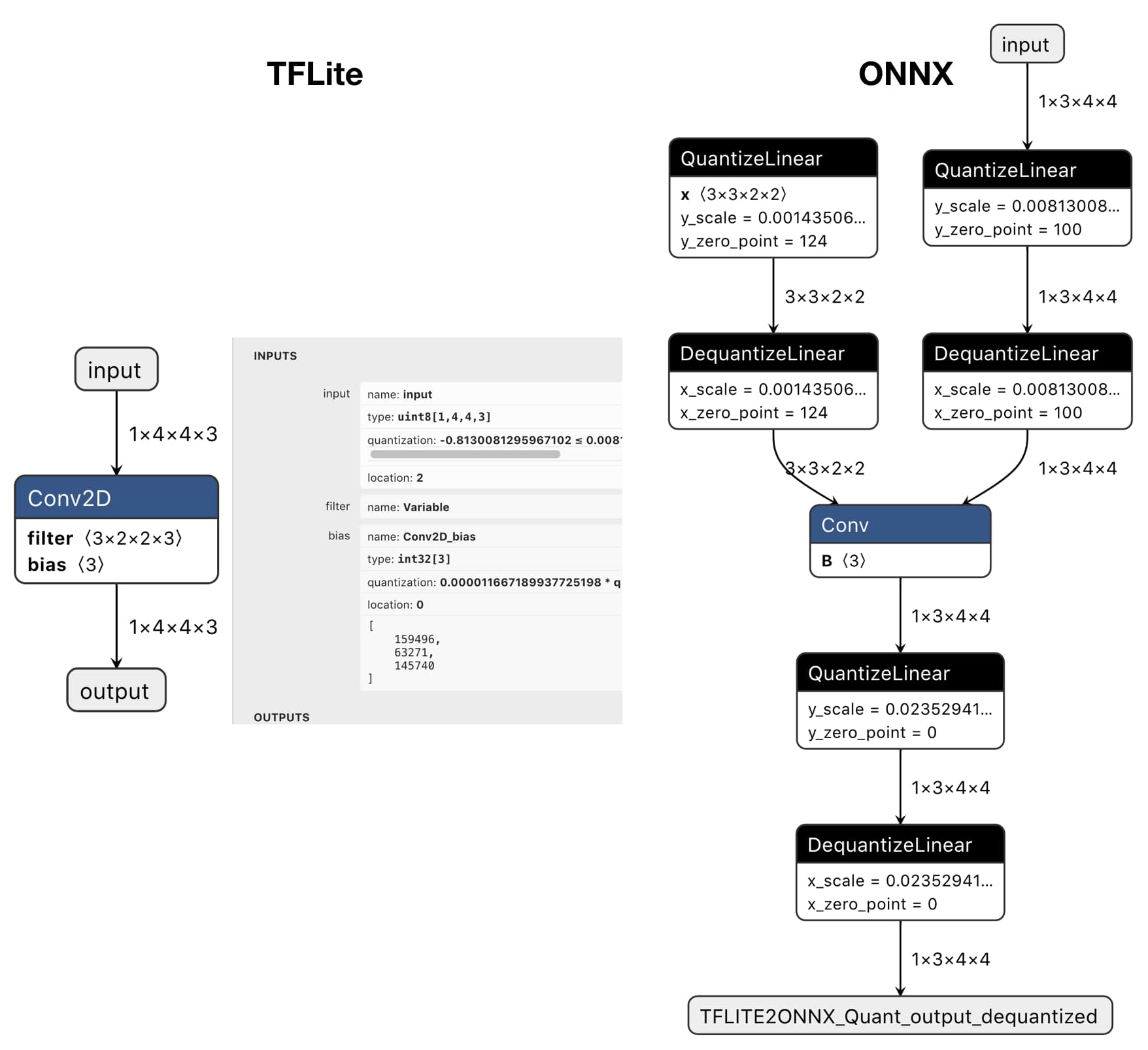 Figure 6: Quantized ONNX model generated by TFLite2ONNX
Figure 6: Quantized ONNX model generated by TFLite2ONNX
The framework that takes the ONNX model can decide how to enable the quantized ONNX model. They can either convert the quantized graph back to non-quantized, or optimize out the quantization pattern with its quantized version operator for better performance.
The Implementation
TFLite2ONNX is a very simple package that includes only ~2000 lines of code as of v0.3. The code is divided into several parts: dedicated converter class for each TFLite operator; data layout and quantization handling that is managed at Graph level; helpers or wrappers such as Tensor, Layout.
As of v0.3, many Convolution Neural Networks have been enabled. We maintain a test that includes a subset of them. About 20 TFLite operators are supported. Python interface together with a command-line tool is available.
If some operators are not supported yet, you may request a new operator. It would be great if you can help to enable new operators, please join us with How to enable a new operator.
The limitation includes:
- RNN or control flow networks have not been enabled. We do plan this for the next milestone.
- No support for controlling the operator set of the generated ONNX model. To manage a simple package, we plan not to support multiple operator set generation, but leave that work to the ONNX Version Converter.
- Many operators are not supported yet. We hope that the community can share a joint force on this, welcome to contribute! To make this easy to happen,
tflite2onnxhas a detailed document of enabling new operators.
You can find more stories about the development on GitHub issues that are tagged with Story.


